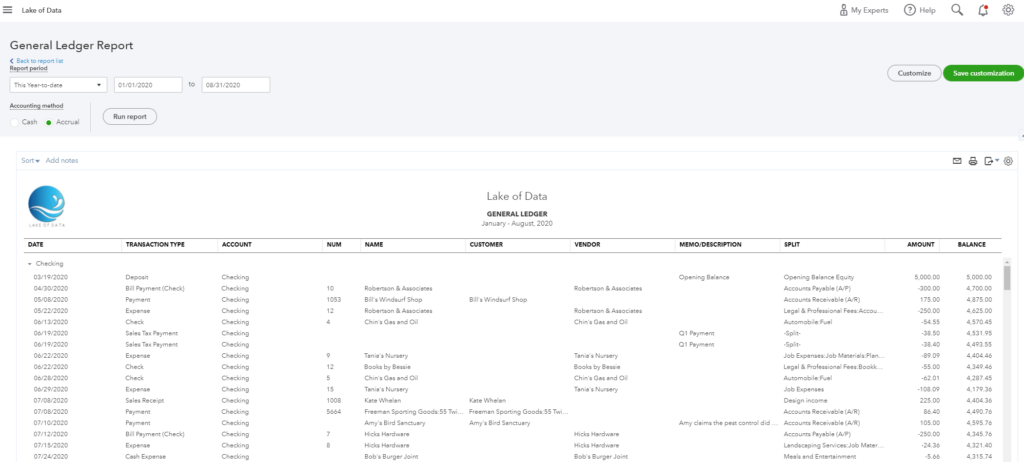
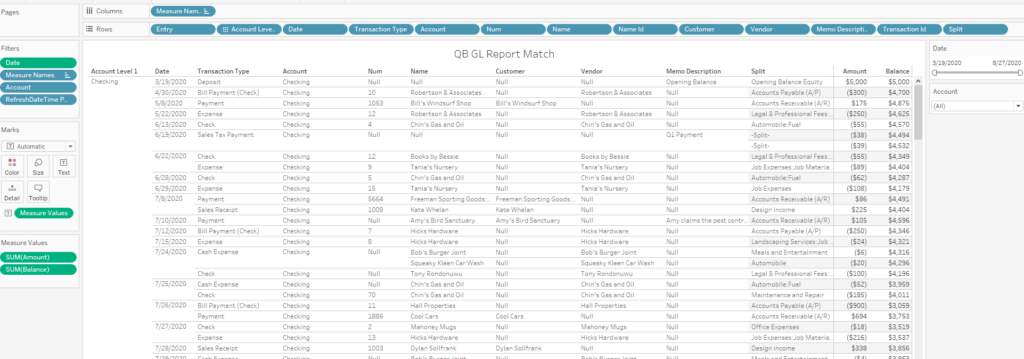
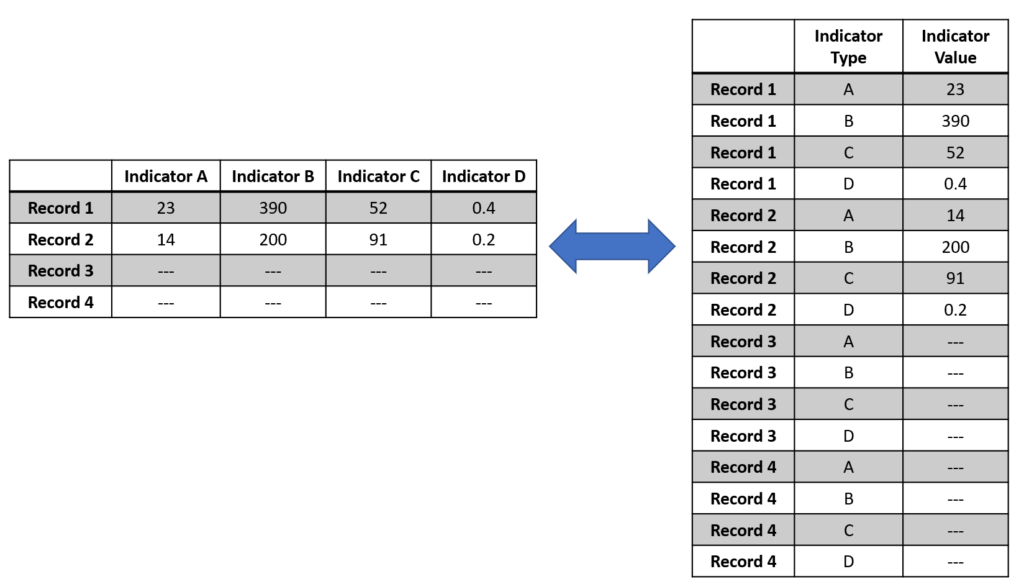
Data for analytics can be structured in two different ways: Wide or Long. Here is an illustration of the two types of format for the same data set:
When would you use one vs. the other? In general, wide models work better for analytical models and offer a better visual layout for humans, whereas the long model works better for columnar DBs like Snowflake, Redshift or Tableau. Their engine is optimized to crunch data at scale within columns.
Now suppose you use Snowflake as a staging area for your analytics, which I highly recommend. You ought to write your data in the Long format. How do you perform that conversion, sometimes called reshaping a table from wide to long? That operation is also called to transpose (Alteryx), unpivot (Snowflake, BigQuery), pivot Columns to Rows (Tableau Prep) or melt a table (Panda). We will also cover the flip side operation, from Long to Wide, also called to cross tab (Alteryx), pivot (Snowflake, BigQuery, Panda) or pivot Rows to Columns (Tableau Prep).
Let’s get practical with a real data set!
Continue reading