
Whether you work in B2B or B2C, getting a better understanding of customer or account transactions in sequence is core. Customer cohorts will show you how well you are doing acquiring new customers, but also do they conduct repeat business with you. Product sequence will help you identify which products are getting traction with your customers: are the sales for one product or for a category just first time trials or do customers come back for repeat purchases of the same product? Working with many references / SKUs, many orders and many customers will bring Excel down to its knees before you know it… You need a solution that can scale!
In this post, I will use Snowflake as a database and Tableau with its standard demo SuperStore data set, but this logic is applicable to any SQL database and any BI product really… First part will show how to easily distinguish new customers from repeat business; second part will show how to identify products within orders by their sequence, and that is less easy… Also, note that I chose to develop the necessary calculations in SQL, but there are certainly ways to perform those calculations in memory in Tableau with Table Calcs, but that is out of scope for today.
SuperStore Tableau data source
Delivered with each install of Tableau Desktop, I loaded the table to Snowflake and started to query it with:
// Step 0: Show Orders details by Customers
select "Customer Name","Order_Date","Order ID","Product Name","Quantity"
from "INTERNAL"."PUBLIC"."SuperStore"
order by 1,2;
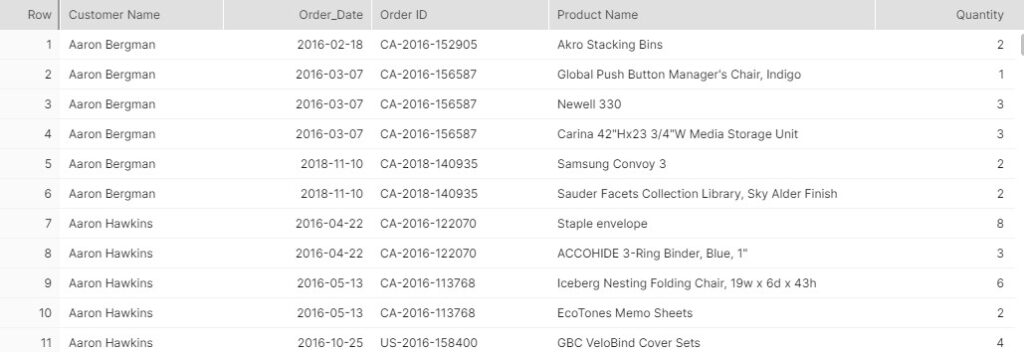
I see that I have a series of orders from different customers, each with line items, showing transactions with different products in various quantities. Here is the evidence of multiple orders per customer and multiple line items per order:
// Step 1: Show multiple Orders by Customers
select "Customer Name","Order_Date","Order ID", count(distinct "Order ID") as Orders, SUM(1) as "Line Items"
from "INTERNAL"."PUBLIC"."SuperStore"
group by 1,2,3
order by 1,3;
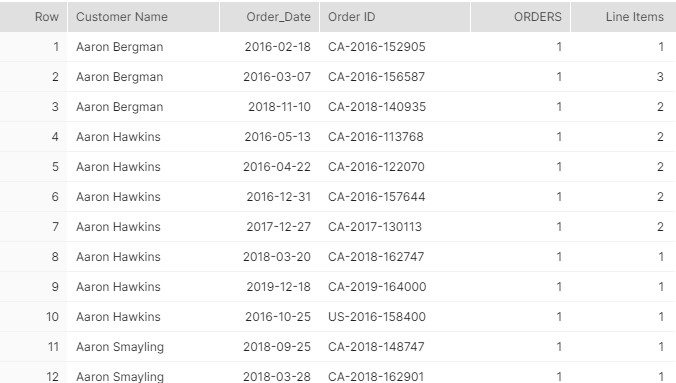
Looking at rows 4 and 5, I realize that orders, despite being sorted by Order ID, appear in a random order. Let’s add an customer Order Rank to use in Tableau, thanks to the wonderful Window functions:
// Step 2: Show rank of Orders by Customers
select "Customer Name","Order ID","Order_Date",DENSE_RANK() OVER (PARTITION BY "Customer Name" ORDER by "Order_Date") as "Order Rank", count(distinct "Order ID") as Orders,SUM(1) as "Line Items"
from "INTERNAL"."PUBLIC"."SuperStore"
group by 1,2,3
order by 1,3;
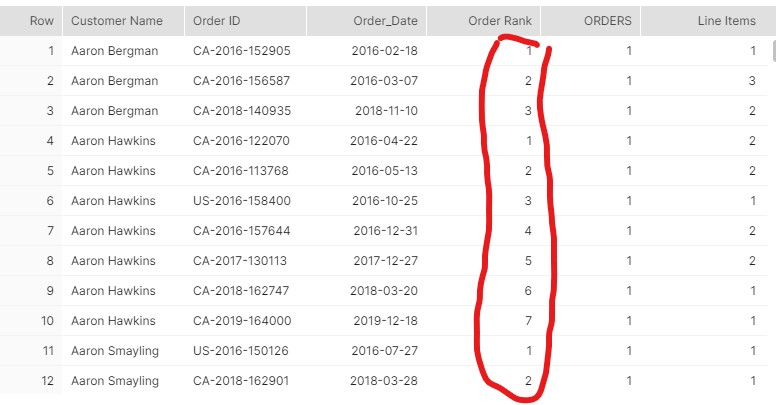
Works as intended, let’s enhance the SuperStore order table with that column, as well as with the first order date we will use for cohorts:
--- enhance table to include Rank and first order date for Customer Cohort
CREATE OR REPLACE TABLE "INTERNAL"."PUBLIC"."SuperStore" AS
select *,DENSE_RANK() OVER (PARTITION BY "Customer Name" ORDER by "Order_Date") as "Order Rank",First_Value("Order_Date") OVER (PARTITION BY "Customer Name" ORDER by "Order_Date") as "Customer Cohort"
from "INTERNAL"."PUBLIC"."SuperStore"
;
Now let’s see how we can use the enhanced table with Tableau or other BI tools.
Customer Cohorts Scenarios
I have a lot of accounts, which is a good thing, and I’d like to understand if my acquisitions strategies are working: am I acquiring new customers, and how are they contributing compared to the previous cohorts. Using the order table from SuperStore and a bit of SQL, I can easily obtain the traditional triangle view with customers grouped by the month they first ordered from me, and columns with their revenue for each subsequent month:
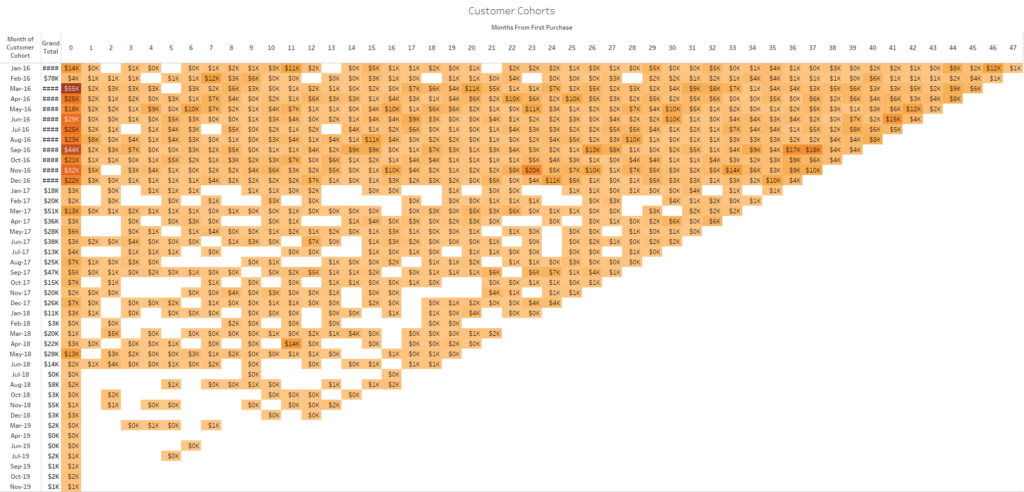
Or a more visual version, more Tableau orthodox:
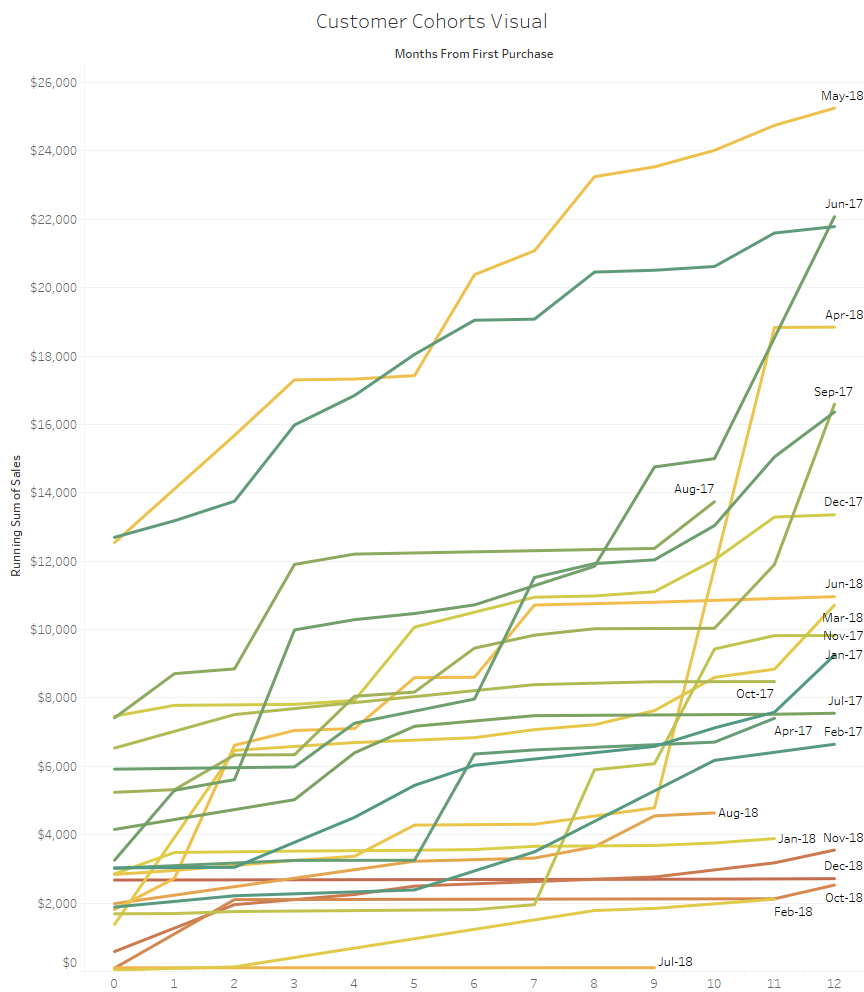
This lets me easily compare and observe the performance of 2 years worth of customer monthly cohorts over their first 12 months of activity with me. I can easily pick out April and May 18 customers which stand out from their peers.
Technically in Tableau, since the Customer Cohort object is a date, I can chose on the fly to group it by week, Month, Quarter, Year… As to the Months From First Purchase, it is simply that Tableau formula:
datediff('month',[Customer Cohort],[Order Date],'monday')
With the other extra column I added, Order Rank, I can now easily distinguish orders coming from new vs. repeat customers:
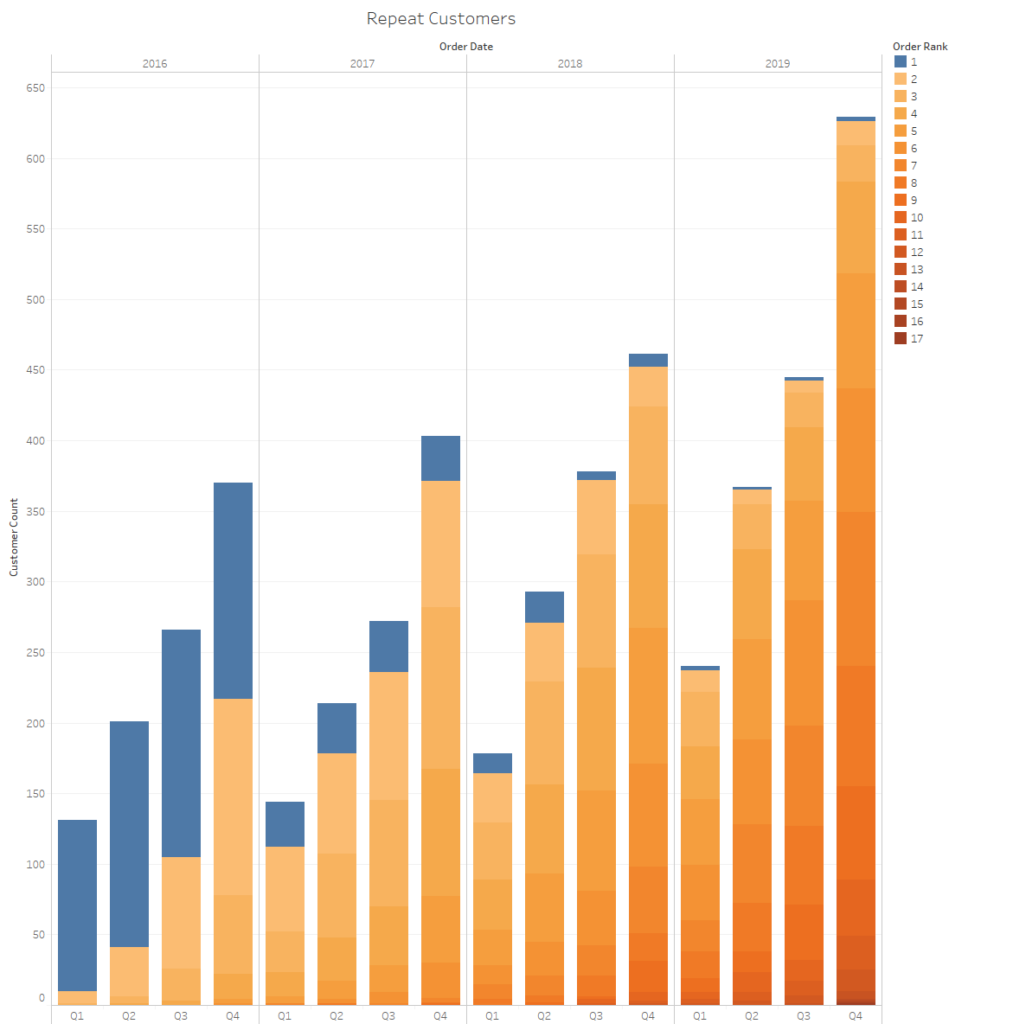
Orders from new customers being in blue, the fictional manager of the SuperStore should worry about his business in 2019: she has a lot of repeat business but hardly any fresh blood in her customer portfolio… Using the Order Rank, I can also very easily identify the most loyal customer by filtering on the 17:
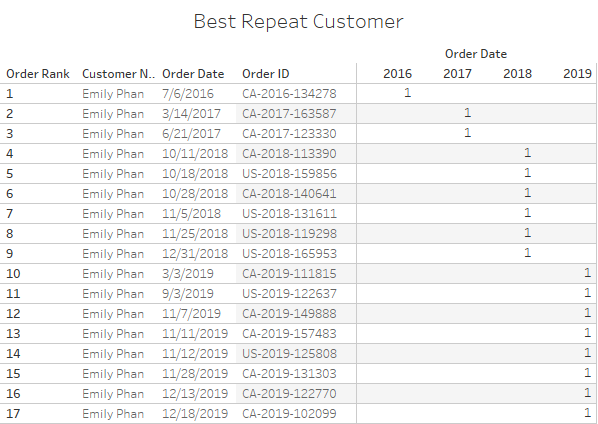
I hopefully demonstrated that the addition of those columns with sequence counts, greatly enhances the possibilities of analysis within Tableau, without destroying any information from the orders, with all filters remaining operational… Now, let’s dig deeper with a similar sequence analysis, but this time on products. Things do get more complicated as a product sequence still requires to take into account the customer…
Product Sequence Scenarios
Focusing now on Products, I need to identify which in my large portfolio are getting purchased repeatedly by the same customers. It could be an indication of quality, of market fit, or an opportunity to offer customers a subscription. Think in the context of Amazon.com: creation of a Subscribe & Save SKU, or simply computing a relevant Buy Again suggestion. In conclusion, I need a Product Rank indicator for each customer, across their orders to achieve this type of viz:
That viz shows for each quarter, which share of the volume of units sold was a first time for a given customer, like a share of trials. Also, note that I need some agility here: I may analyze a single product, a category or use any attribute of the order really, like category and year here:
Checking out the Order table a bit randomly, I stumble upon this:
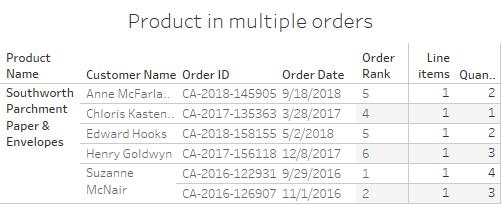
This proves that the same product can be found in multiple orders, which is fortunate, but also that there are some repeat customers, such as Suzanne McNair, who bought the same product in different orders. So let me check holistically how often this occurs in my data set, using this query:
// Step 3: Show all customers who ordered a product more than once
select "Customer Name","Product Name",SUM(1) as "Line Items"
from "INTERNAL"."PUBLIC"."SuperStore"
group by 1,2
having "Line Items">1
order by 1,2;
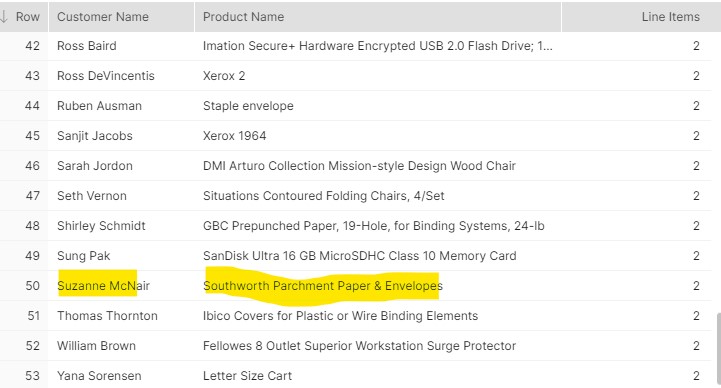
data set definitely has some repeat purchase of the same SKUs, and I find Suzanne as expected. Therefore, I can use the Window Functions again to count Products for each Customer across Orders:
// Step 4: Show rank of Products by Customers
select "Customer Name","Order_Date","Order ID","Product Name",RANK() OVER (PARTITION BY "Customer Name","Product Name" ORDER by "Order_Date") as "Product Rank",SUM(1) as "Line Items"
from "INTERNAL"."PUBLIC"."SuperStore"
group by 1,2,3,4
order by 1,2;
And let me check that this works for Suzanne:
// Step 5: Show rank of Products by Customers: check Suzanne
select "Customer Name","Product Name","Order_Date",RANK() OVER (PARTITION BY "Customer Name","Product Name" ORDER by "Order_Date") as "Product Rank",SUM(1) as "Line Items"
from "INTERNAL"."PUBLIC"."SuperStore"
WHERE "Customer Name"='Suzanne McNair'
group by 1,2,3
order by 1,2;
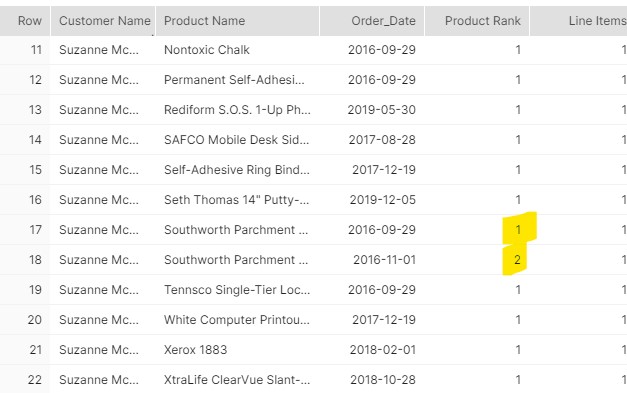
That looks pretty good, right? Hmm, aren’t we overlooking something? What about quantities?
// Step 6: Show rank of Products by Customers with Quantities: WRONG!
select "Customer Name","Order_Date","Order ID","Product Name",RANK() OVER (PARTITION BY "Customer Name","Product Name" ORDER by "Order_Date") as "Product Rank",SUM(1) as "Line Items",SUM("Quantity")
from "INTERNAL"."PUBLIC"."SuperStore"
WHERE "Customer Name"='Suzanne McNair'
group by 1,2,3,4
order by 1,4;
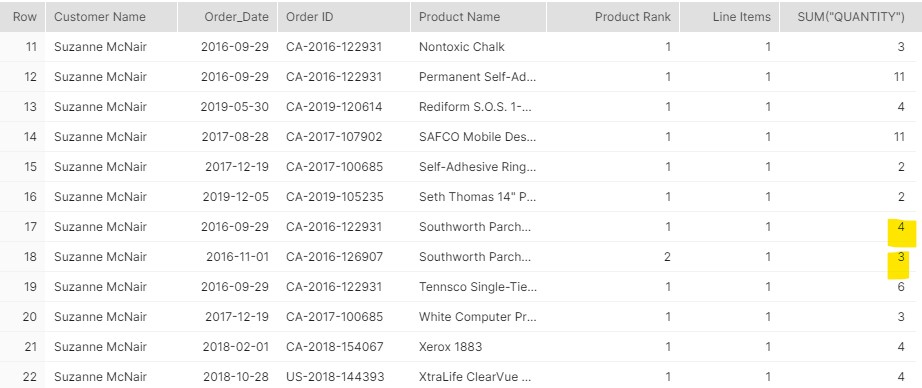
Is that a fringe case? Let’s check the average quantity per order line item, the current granularity of the table:
select avg("Quantity") from "INTERNAL"."PUBLIC"."SuperStore";
That command returns 3.78… I can only admit that Product Rank approach does not work because Suzanne’s first order actually had 4 Parchments and the second order should therefore start at Product Rank =5. That also implies that I need to change the granularity of the Orders table because having quantities>1 on a single line item breaks the counts: I need 7 rows with a Quantity of 1 instead of 2 rows with 4+3… I already know that my target table should get 9,994 rows X 3.78=37,873 rows.
So now, how do I proceed to create those extra 27k rows? That would be asking a lot from Excel and that would not be repeatable… Alteryx users can use the great Generate Rows tool, but I want to stay within SQL and spare myself the pain of exporting and especially re-importing the expanded data… The proper SQL approach I will detail was not instinctive to me, hence the motivation to write that post! It starts with the creation of a simple, dare I say dumb, number table, which comprises of only 1 column and 1 row per number, using recursive CTEs:
// Step 7: Create Numbers Table
CREATE TABLE "INTERNAL"."PUBLIC"."NUMBERS"(Number int not null) ;
// Step 8: Populate Numbers Table
insert into "INTERNAL"."PUBLIC"."NUMBERS"(Number)
WITH Nums(Number) AS
(SELECT 1 AS Number
UNION ALL
SELECT Number+1 FROM Nums where Number<100
)
select Number from Nums;
Snowflake limits by default CTE recursive iterations to 100 to protect their infrastructure from clumsy infinite loops. This is more than enough in my case since the average quantity is only 3.78 and the maximum is 14. Should you need more than 100 records, you can insert more this way, 100 at a time:
// Insert 100 additional rows insert into "INTERNAL"."PUBLIC"."NUMBERS"(Number) WITH Nums(Number) AS (SELECT 101 AS Number UNION ALL SELECT Number+1 FROM Nums where Number<200 ) select Number from Nums;
And yes, alternatively, I could have created a CSV with a spreadsheet with however many rows I need and uploaded it, but that’s not as elegant, imho… Now I can use that Numbers table to join the Order table against the quantities, and therefore create in a swift few lines of code all the extra Order rows I need, in a new table called SuperStore_Products:
// Step 8: Prepare Table with one additional row for each line item where quantity>1
CREATE OR REPLACE TABLE "INTERNAL"."PUBLIC"."SuperStore_Products" AS
SELECT SOURCE.*,N."NUMBER" as "Item Count"
FROM "INTERNAL"."PUBLIC"."SuperStore" AS SOURCE
JOIN
"INTERNAL"."PUBLIC"."NUMBERS" N
ON N.Number <= SOURCE."Quantity";
Looks good! Now I just need a couple of edits to split the quantities and other dependent indicators between the new rows, to ensure the totals in Tableau will remain accurate:
// Step 9: Update line items to keep totals
UPDATE "INTERNAL"."PUBLIC"."SuperStore_Products"
SET "Sales" = "Sales"/"Quantity";
UPDATE "INTERNAL"."PUBLIC"."SuperStore_Products"
SET "Profit" = "Profit"/"Quantity";
UPDATE "INTERNAL"."PUBLIC"."SuperStore_Products"
SET "Quantity" = 1;
Now that I have a clean table with a single product unit sold per row, I can enhance the table with the long awaited Product Rank column:
// Step 10:
CREATE OR REPLACE TABLE "INTERNAL"."PUBLIC"."SuperStore_Products" AS
select *,RANK() OVER (PARTITION BY "Customer Name","Product Name" ORDER by "Order_Date","Item Count") as "Product Rank"
from "INTERNAL"."PUBLIC"."SuperStore_Products";
Let me test it for Suzanne with a before and after picture:
// Step 11: Test Table Before
select *,RANK() OVER (PARTITION BY "Customer Name","Product Name" ORDER by "Order_Date") as "Product Rank"
from "INTERNAL"."PUBLIC"."SuperStore"
WHERE "Customer Name"='Suzanne McNair' AND "Product Name"='Southworth Parchment Paper & Envelopes'
ORDER BY "Product Rank" DESC;

7 units for sales of 37. Let’s compare with the picture after transformations:
// Step 12: Test Table After select * from "INTERNAL"."PUBLIC"."SuperStore_Products" WHERE "Customer Name"='Suzanne McNair' AND "Product Name"='Southworth Parchment Paper & Envelopes' ORDER BY "Customer Name","Product Name","Product Rank";

Sales still total 37, quantity 7 and the Ranks are correct. Icing on the cake, I did not destroy any information from the details of the orders! And obviously, this works at scale…
For the fans of Alteryx INDB tools (count me in) who wonder if that manipulation could be done INDB, the answer is Yes and No. It takes indeed an alternative sequence to get around a sizable INDB limitation: the Join tool only allows = but no < condition. Therefore, you must input the join in the connection tool:
SELECT * FROM "INTERNAL"."PUBLIC"."SuperStore" AS SOURCE JOIN "INTERNAL"."PUBLIC"."NUMBERS" AS N ON N.Number <= SOURCE."Quantity"
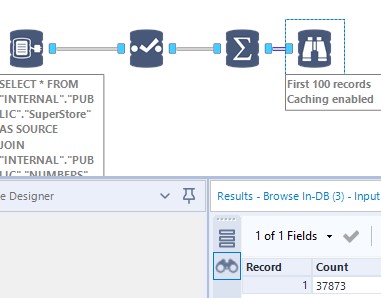
And then use the Formula tool to fix the columns and Write Data INDB to commit the results to Snowflake … All that to say, that you do need to understand the SQL logic detailed above…
Here is the whole SQL sequence in one go for easier Copy and Paste to Snowflake: