
What I mean by history table is what is commonly called a Slowly Changing Dimension, or SCD table of type 2, which retains efficiently all the previous values I decide to track, for accurate historical reports. Why do we care for historical values? In a SFDC CRM context, suppose you are reporting on the number of opportunities processed by each rep over a year, based on the opportunity creation date. If the opportunity owner changes over time before close, you will assign the opportunity to the bucket of the most recent owner, instead of the legitimate first owner, who won’t get the credit. A SCD type 2 setup will archive all the owner values each opportunity took over time, and will store those records only if there was a change. That represents much less storage and processing resource than a daily snapshot table. I need to decide early which columns I want to track if they are likely to change, here in blue for that example:

Now suppose you have a simple setup of type: Fivetran copies SFDC table Opportunity to Snowflake, and overwrites all changes originating from SFDC. How do you build that history table?
Start by congratulating yourself, because you made a great choice when you picked Fivetran! In some cases, it will take a simple click to get that table created and populated, using the new Fivetran feature called History Mode. It is indeed available for that SFDC Opportunity table, but unfortunately, that is not the case for every source system Fivetran connects to: that feature is rolled out gradually for each data source.
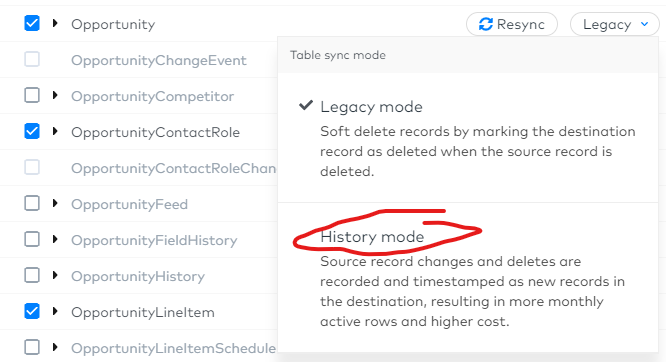
There will be situations when it is not available for your use case, and you might not even have Fivetran in the first place… Sad but true, I feel for you if you are stuck with Stitch… So what now? You still deserve some congrats because you have Snowflake, and following the guidance in that post, you will be able to create, and most important update, that history table with little effort.
We will leverage here some wonderful functionalities, specific to Snowflake and its cloud first design:
- Streams: which will identify and record DML changes in the table, including inserts, updates, deletes and metadata about each change. A stream maintains only the delta of the changes; if multiple DML statements change a row, the stream contains only the latest action taken on that row.
- Merge: To upsert (update/insert) those changes to the history table
- Tasks: to schedule and automate the processing, without additional software. User-defined tasks allow scheduled execution of SQL statements. Tasks run as per specified execution configuration, using a subset of CRON utility syntax for selecting the frequency.
With Fivetran, or any other ELT tool really, syncing a table to Snowflake, the data pipeline setup would look something like this:
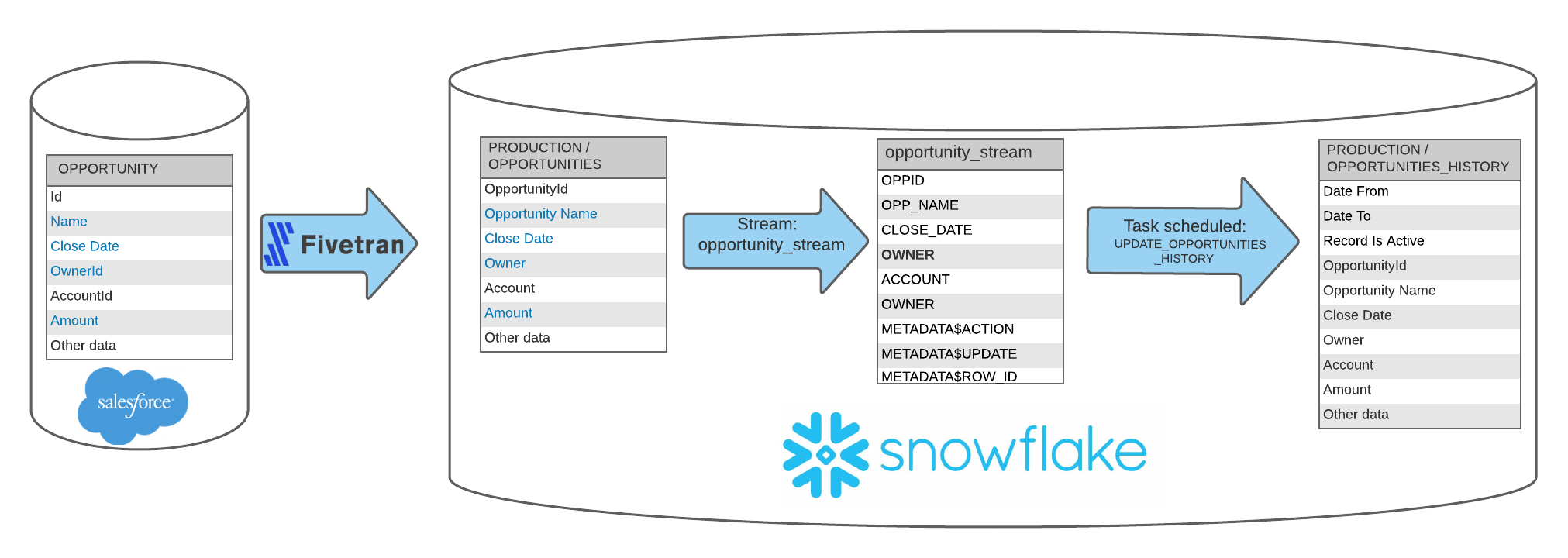
Demo Overview
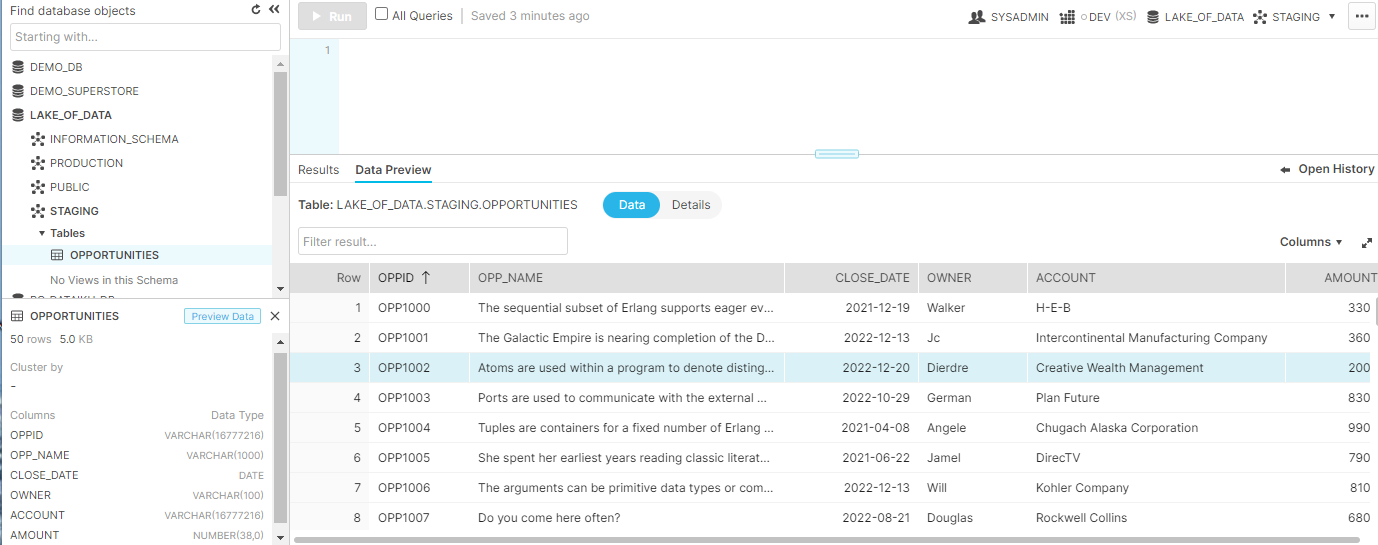
For the purpose of demoing the process without actually using Fivetran, just flat files, I created a table of 50 phony opportunities, available to download from here, that I loaded to a Staging schema to simulate delta loads from an ELT:
It will be followed by a delta load that will modify 3 opportunities and add 3 net new ones. Changes are highlighted:
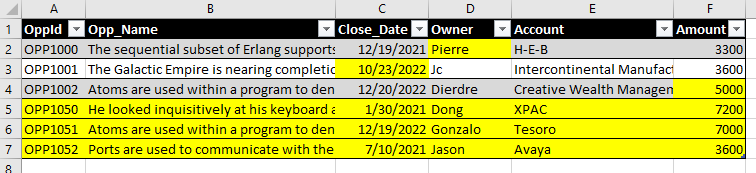
I change Owner, Close Date and Amount. Since I am using flat files for that demo, the data pipeline will follow this slightly different sequence:
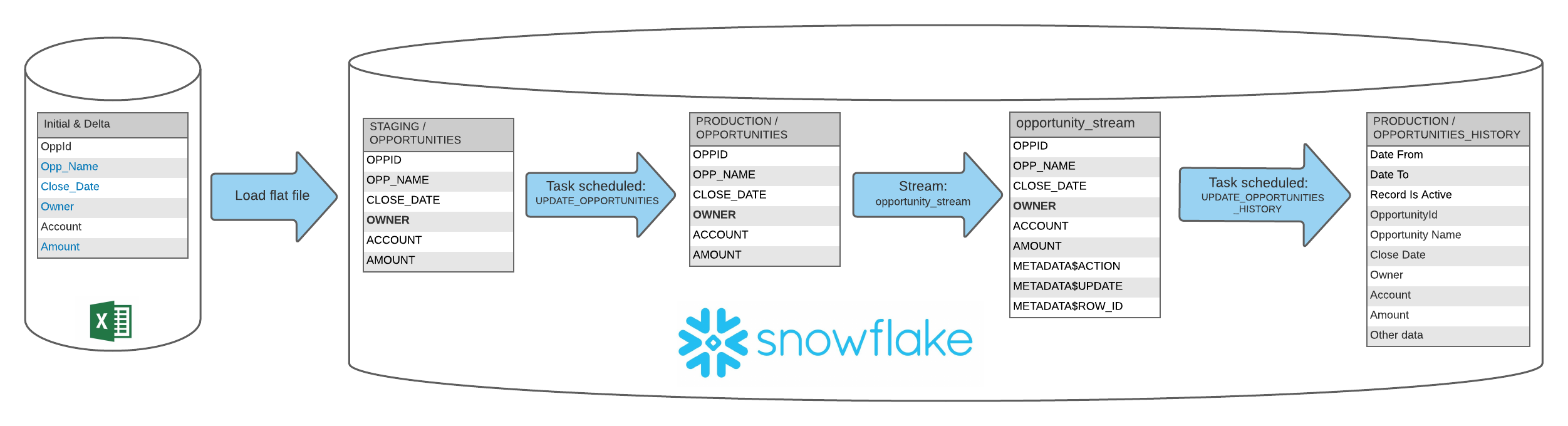
We have there a Staging.Opportunities table with all net new transactions, which will update a Production opportunities table through a Merge, and the changes in that Production Opportunities table will be captured by the Stream, which we will then use to calculate and populate the SCD2 entries into the Production Opportunities_History table.
Step 1: Initialize Production.Opportunities and Production.Opportunities_History tables
I have 50 opportunities loaded into Staging.Opportunities and I will simply clone the table to create Production.Opportunities. I will then proceed to initialize the History table, using today’s date as Date_From, NULL for Date_To and setting them all as Active
-- Initialize OPPORTUNITIES table in Production
CREATE OR REPLACE TABLE "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES" CLONE "LAKE_OF_DATA"."STAGING"."OPPORTUNITIES";
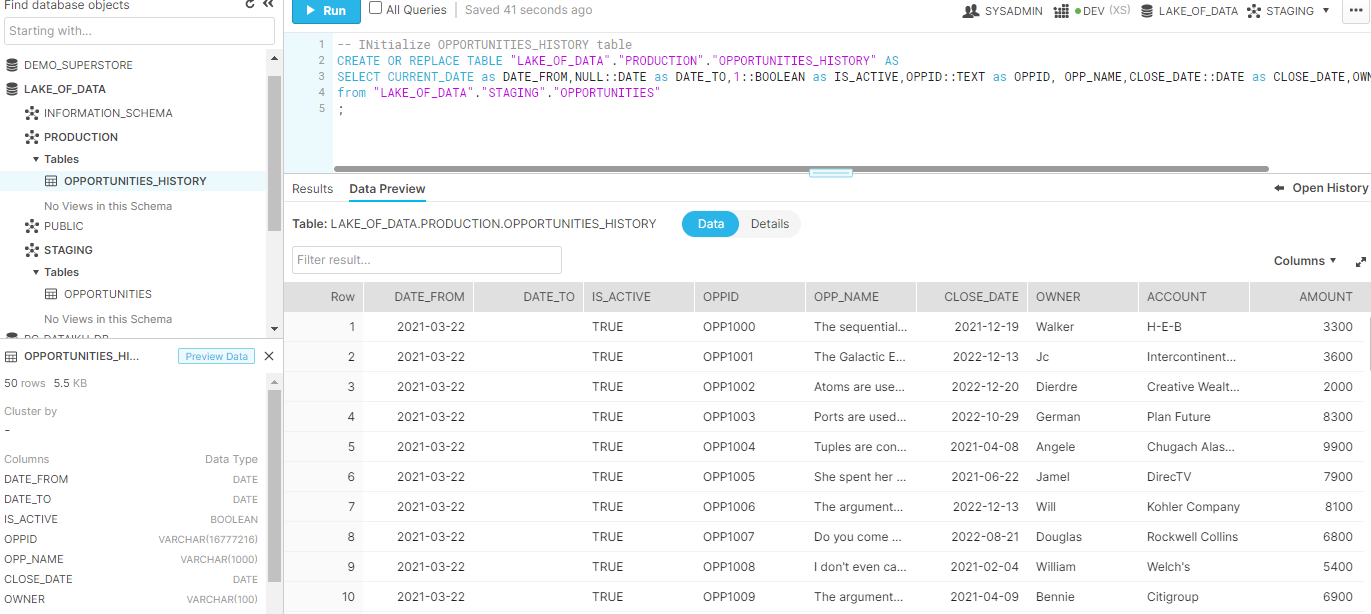
-- Initialize OPPORTUNITIES_HISTORY table
CREATE OR REPLACE TABLE "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES_HISTORY" AS
SELECT CURRENT_DATE as DATE_FROM,NULL::DATE as DATE_TO,1::BOOLEAN as IS_ACTIVE,OPPID::TEXT as OPPID, OPP_NAME,CLOSE_DATE::DATE as CLOSE_DATE,OWNER,ACCOUNT,AMOUNT
from "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES";Now that each of those table have 50 records each, I won’t need to run that code anymore, it is just used for the initial snapshot. Here is how it looks now:
Step 2: Create Stream to start capturing changes
Very simple syntax, but make sure you set the proper database and schema before you run it:
--Create Stream to track changes
create or replace stream opportunity_stream on table "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES";
-- confirm creation and definition
Show Streams;
DESCRIBE STREAM opportunity_stream;
-- confirm stream is empty for now
select * from opportunity_stream order by OPPID;Step 3: Load delta records to Staging.Opportunities
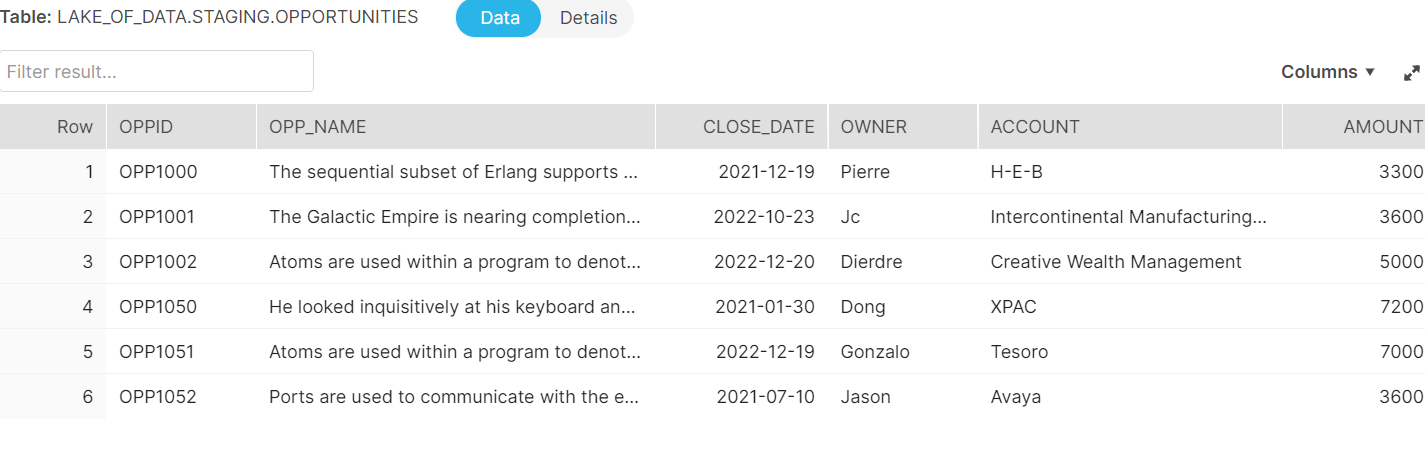
Note how the 3 first (OPP1000 to 1002) are existing in the Production.Opportunities table, and the next 3 are new.
Step 4: Create Task to update Production.Opportunities with Staging.Opportunities
Here we will use a script to create a task that will automatically check on the staging table and merge the records with the Production table:
-- Update of the production opportunities Table
CREATE OR REPLACE TASK UPDATE_PRODUCTION_OPPORTUNITIES
WAREHOUSE = DEV
SCHEDULE ='USING CRON 30 23 * * * America/Los_Angeles' //11:30pm every day
COMMENT = 'Update OPPORTUNITIES table with edits and new records from Staging OPPORTUNITIES flat file'
As
Merge into "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES" t1 using "LAKE_OF_DATA"."STAGING"."OPPORTUNITIES" t2 on t1.OPPID = t2.OPPID
when matched then update set t1.OPP_NAME=t2.OPP_NAME,t1.CLOSE_DATE=t2.CLOSE_DATE,t1.OWNER=t2.OWNER,t1.AMOUNT=t2.AMOUNT
when not matched then insert (OPPID,OPP_NAME,CLOSE_DATE,OWNER,ACCOUNT,AMOUNT) values (t2.OPPID,t2.OPP_NAME,t2.CLOSE_DATE,t2.OWNER,t2.ACCOUNT,t2.AMOUNT)
;Note the Schedule setting which kicks off the job once a day at 11:30PM. The CRON feature gives you a lot of flexibility to pick once a day, a weekday, once a month and more. Snowflake’s help on that topic is very helpful.
Once that task has run, or if you just run the Merge instruction command prior to setting up the task, you should get this response:

And then you can check the content of the stream using:
select * from opportunity_stream order by OPPID;and will get this:

As expected, we have the first 6 rows reflecting the UPDATES to existing records, with a INSERT or DELETE METADAT$ACTION and rows 7 to 9 for the INSERTs of the net new opportunities. Now the next step is to use those records to update the History table.
Step 5: Create Task to update Production.Opportunities_History with Stream
-- Update of the OPPORTUNITIES_HISTORY table
CREATE OR REPLACE TASK UPDATE_PRODUCTION_OPPORTUNITIES_HISTORY
WAREHOUSE = DEV
COMMENT = 'Update OPPORTUNITIES_HISTORY table with modified and new records from OPPORTUNITIES in Production using Stream'
AFTER UPDATE_PRODUCTION_OPPORTUNITIES
WHEN SYSTEM$STREAM_HAS_DATA('opportunity_stream')
As
Merge into "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES_HISTORY" t1 using opportunity_stream t2 on t1.OPPID = t2.OPPID AND t1.OPP_NAME = t2.OPP_NAME AND t1.CLOSE_DATE = t2.CLOSE_DATE AND t1.OWNER = t2.OWNER AND t1.AMOUNT = t2.AMOUNT
when matched AND (t2.METADATA$ACTION='DELETE') then update set DATE_TO=CURRENT_DATE,IS_ACTIVE=0
when not matched AND (t2.METADATA$ACTION='INSERT') then insert (DATE_FROM,DATE_TO,IS_ACTIVE,OPPID,OPP_NAME,CLOSE_DATE,OWNER,ACCOUNT,AMOUNT) values (CURRENT_DATE,NULL,1,t2.OPPID,t2.OPP_NAME,t2.CLOSE_DATE,t2.OWNER,t2.ACCOUNT,t2.AMOUNT)
;That task is another MERGE command, taking place automatically after the previous task, as I highlighted in bold. The extra command WHEN SYSTEM$STREAM_HAS_DATA(‘opportunity_stream’) will not start the task when the stream has nothing, which is convenient to save some Snowflake credits if you plan to run that task several times a day.
I also highlighted the extra joints in the MERGE command, as they are critical: they check on every field/column where you need to track changes, and are used below for the when not matched part of the command. It basically instructs Snowflake to add a new opportunity record when either OPP_NAME,CLOSE_DATE, OWNER or AMOUNT have changed on an existing opportunity. I can’t stress that enough, as myself got burned badly before: if you don’t include those extra joints, an existing opportunity with a new amount would be shut down with a DATE_TO, but the new record with the new amount will NOT get inserted, only net new opportunities will be inserted. As a result, any updated opportunity will be made inactive for good. This is hard to see when you are dealing with 1,000s of records…
After you run that command, you can run this query:
SELECT * FROM "LAKE_OF_DATA"."PRODUCTION"."OPPORTUNITIES_HISTORY"
WHERE OPPID IN('OPP1000','OPP1001','OPP1002','OPP1050','OPP1051','OPP1052')
ORDER BY OPPID,DATE_FROM;And as expected, you get this:
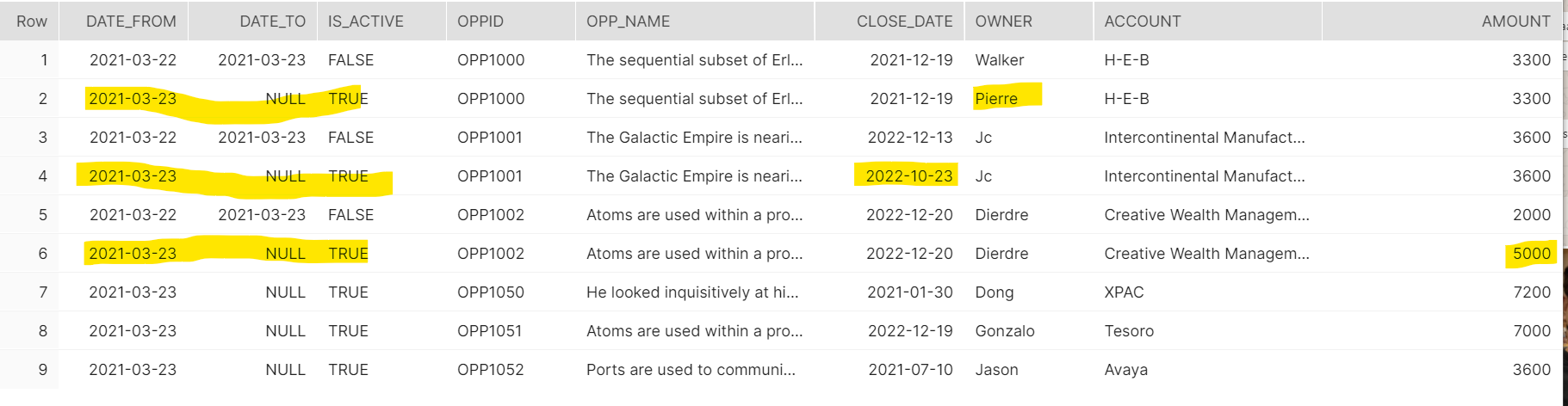
You can now use Production.Opportunities_History in your reports, with the IS_ACTIVE flag making it easy to look at the current set of opportunities, but also looking at a single opportunity evolution throughout the DATE_FROM dimension…
Here is all the Snowflake SQL used in one place: