
Finding duplicate entities at scale in large databases using only names coming from free text boxes is always a challenge in Marketing, common in B2C, often ignored in B2B. Let’s take a simple scenario:
I have a very long list of Contacts/Leads/Customers who self identify, typing their name, organization and email address in open text fields. I need to dedupe those contacts to make sure I don’t email them the same content several times, and I can’t trust the email address as unique identifier as I know some of them use their personal email address, or disposable email addresses and also their professional email address. I will assume here that the combo first + last name is consistent and reliable. Last name alone would not work, as too many last names are common. First+last name is better, but still not unique enough, so I will resort to first+last+org. The challenge is that organizations tend to have multiple spellings, and that is the object of the fuzzy logic to match those.
For illustration, I will use a list of 1,826 organizations spelled distinctly downloaded from here, with many good examples from real life:



I will pretend that I have the same single first+last name tied to all those organizations to illustrate how fuzzy logic will perform. Therefore, I will need to compare 1,826*1,825=3,332,450 pairs of organizations and retain those that are close enough in their spelling, to be considered for consolidation. That is a lot of data to crunch, more than what Excel can handle, but as we will see, a walk in the park for Tableau paired with a data base…
For my demonstration, I will leverage Snowflake, because it is efficient, elegant and offers some built in functions that speed up the development significantly. The first built in function is an algorithm that will measure how close in spelling are the two organizations in each of the 3M+ pairs: the Levenshtein distance. Wikipedia provides that simple example of a distance score of 3 between the strings ‘kitten’ and ‘sitting’:
- kitten → sitten (substitution of “s” for “k”)
- sitten → sittin (substitution of “i” for “e”)
- sittin → sitting (insertion of “g” at the end).
Snowflake has that algorithm built in the function EditDistance, but it is fairly easy to Google scripts for alternative SQL data bases. Note that EditDistance works in any language for the string. I can use it to figure out which of the pairs generated through a self join has less than 5 characters of Distance:
WITH “Source” AS (Select “PublicSectorBodyName” AS “Source_Org”,(‘John Doe’) AS “Source_Name”
from “DATABASE”.”PUBLIC”.”Organizations”),
“Target” AS (Select “PublicSectorBodyName” AS “Target_Org”,(‘John Doe’) AS “Target_Name”
from “DATABASE”.”PUBLIC”.”Organizations”)
SELECT *,(editdistance(“Source_Org”,”Target_Org”)) AS “Distance_Score”
FROM “Source” INNER JOIN “Target” ON “Source”.”Source_Name” = “Target”.”Target_Name”
WHERE “Distance_Score” > 0 AND “Distance_Score” < 5
Note the “Distance_Score” > 0 filter to remove the EXACT matches. I can now take that query after testing it in Snowflake, to Tableau and build a new data source as a Custom Query. I will insert a parameter for the distance_score, so that I can try different distance levels and visualize the quality of the matches. And I get instant results thanks to Snowflake muscles:
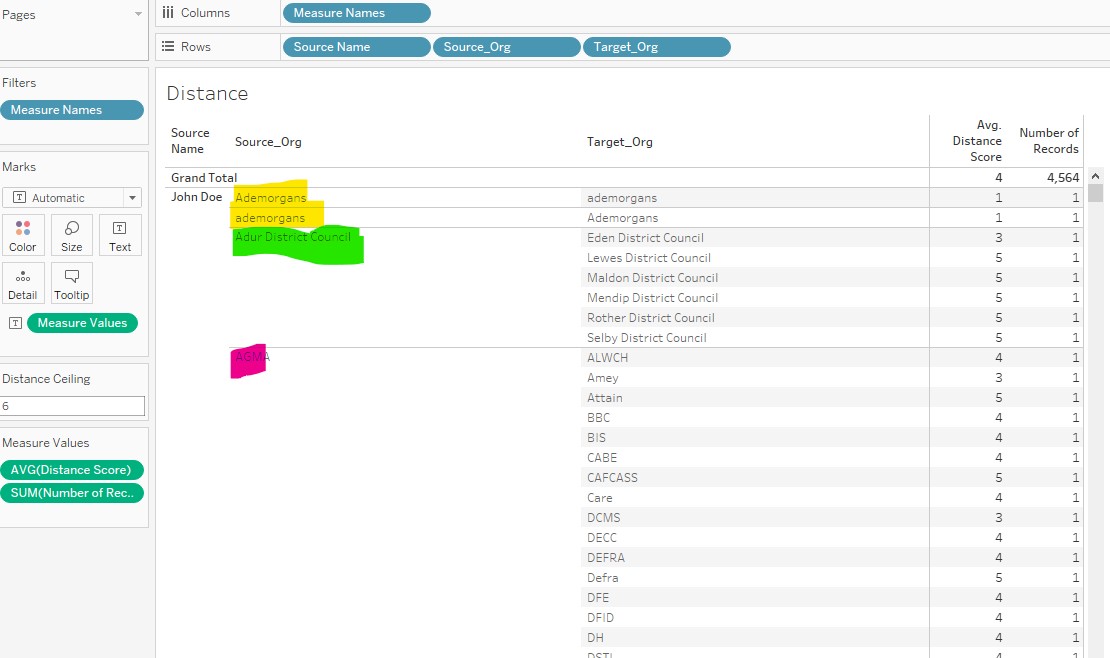
First example in yellow looks pretty good! Ademorgans with or without a capital A (distance=1) should be matched, that’s encouraging…
Second example in green is more concerning: with a maximum score of 5 those short district names are fully replaced, and I get many false positive matches… Not good… Perhaps I can address the issue by reducing the tolerance of the algorithm, that is by lowering the maximum distance to 4?
Third example in pink shows that even with a distance of 4, I will run into the issue of short acronyms which will be all false positives… This will therefore not work as is…
Levenshtein needs some help! We should use it only for comparable strings, and therefore, we can associate it to another standard algorithm which will encode each string as a family: the Soundex algorithm. Soundex is based on the pronounciation of the string, it will take the first letter + following consonants of the first word and assign a digit. It is also built in Snowflake SQL and it is also common enough that it is easy to implement in a variety of SQLs. I can now enhance the SQL query to match only strings pronounced with the same soundex code:
WITH “Source” AS (Select “PublicSectorBodyName” AS “Source_Org”,(soundex(“PublicSectorBodyName”)) AS “Source_Soundex_Code”,(‘John Doe’) AS “Source_Name”
from “DATABASE”.”PUBLIC”.”Organizations”),
“Target” AS (Select “PublicSectorBodyName” AS “Target_Org”,(soundex(“PublicSectorBodyName”)) AS “Target_Soundex_Code”,(‘John Doe’) AS “Target_Name”
from “DATABASE“.”PUBLIC”.”Organizations”)
SELECT *,(editdistance(“Source_Org”,”Target_Org”)) AS “Distance_Score”
FROM “Source” INNER JOIN “Target” ON “Source”.”Source_Name” = “Target”.”Target_Name” AND “Source”.”Source_Soundex_Code” = “Target”.”Target_Soundex_Code”
WHERE “Distance_Score” > 0 AND “Distance_Score” < 5
ORDER by “Source_Soundex_Code” asc
The additions are in bold. After editing the SQL query in Tableau, I now can get this view which is vastly improved, with only 318 matches, and many false positives removed:
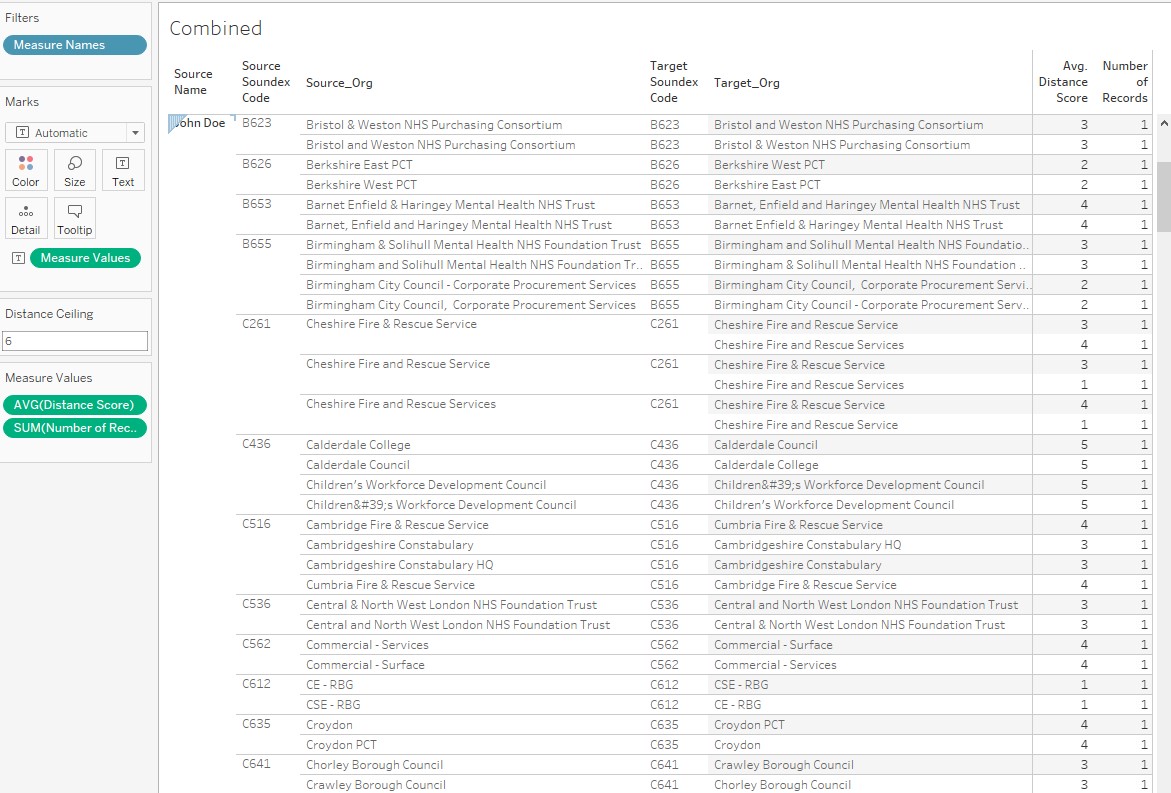
I am only displaying the Soundex codes for illustrations, but they can obviously be concealed without affecting the quality of the match. The match is not perfect, it is fuzzy after all, but based on what I see, I can play with the distance parameter to find the right level of tolerance and optimize the matches.
Please comment if you have suggestions for additional algorithms to further improve matching… I believe there has been many refinements over Soundex…