
Suppose you have a set of transactions, such as Superstore orders for instance, each with one to many line items, with each line item belonging to a product category:
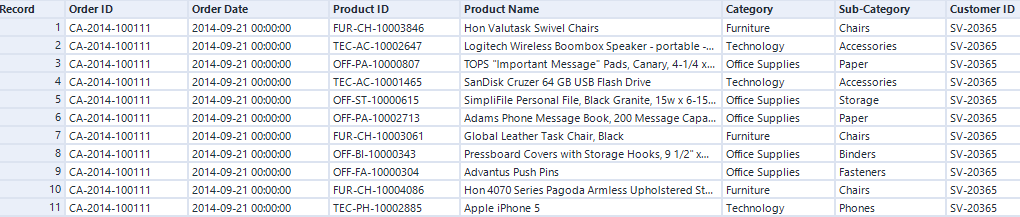
Note that this is a single order with actually 14 line items, but my data set has 10,000 records with 5,009 distinct orders. My goal is to obtain one row per order, a count of line items, and most important, a single field with all categories found in that order to enable filter by keyword:
With Alteryx In Memory, it is pretty easy to accomplish, using the Summarize tool with its convenient Concatenate function:
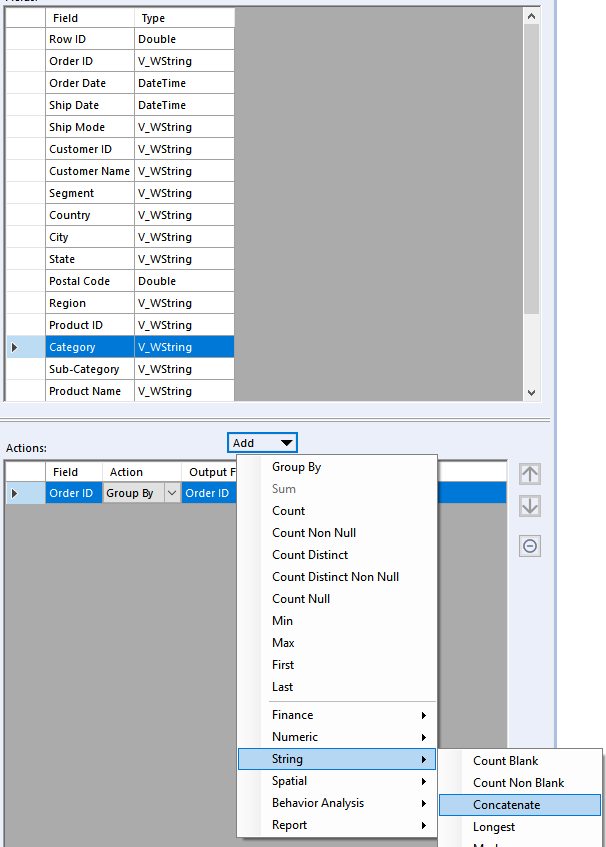
One might be tempted to get the results in one step with this config:
But that would be a bad idea, since if an order has more than one line item in the same category, you would get this:

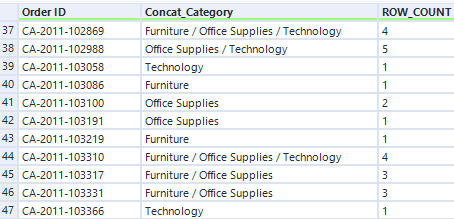
Not very clean… It does indeed require a 2 steps Summarize sequence:
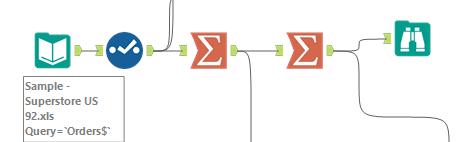
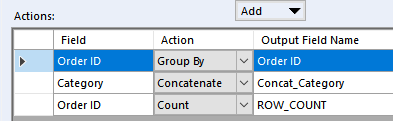
With first Summarize configured this way:
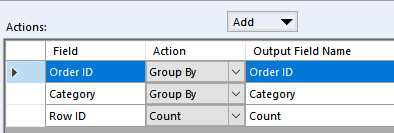
And the second Summarize:
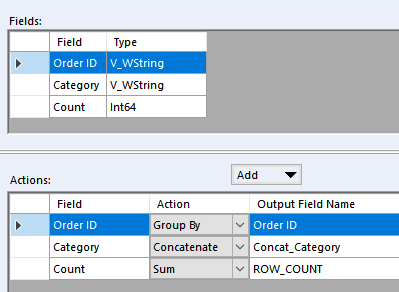
And that same order now gets clean searchable Categories column:

Now, trying to perform the same Summarize with Alteryx INDB might seem tempting, but it does not go very far:
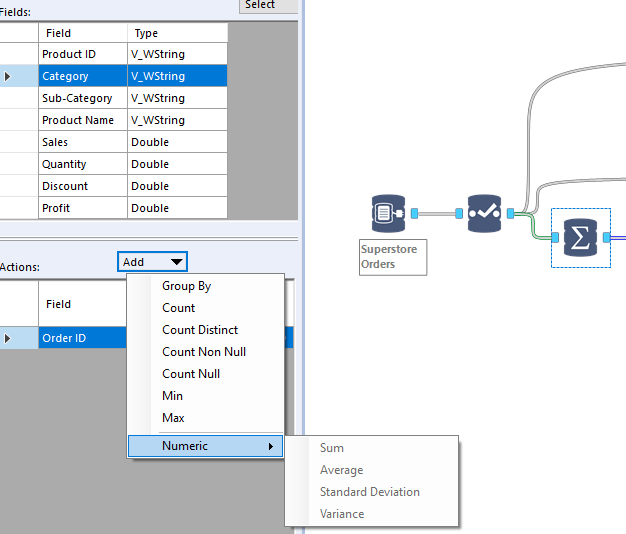
Hmm, where is the concatenate? As often with INDB, we will recourse to Snowflake SQL to accomplish that concatenate, using the not so obvious function LISTAGG, specifically its reliably helpful Window Function flavor:
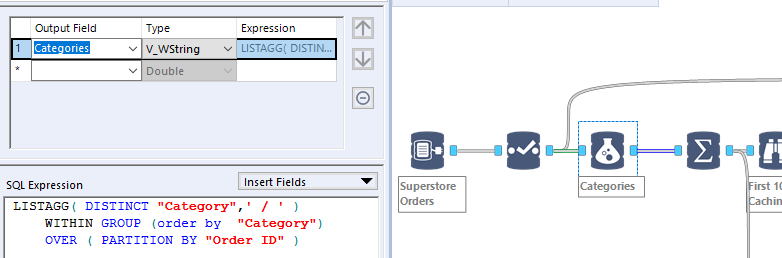
At that point, every line item will have all the categories found in the higher level Order, consistently. Note that the categories are ranked by alphabetical order as well. This consistency does allow us to use a simple Summarize INDB tool to group those line items at the Order level:
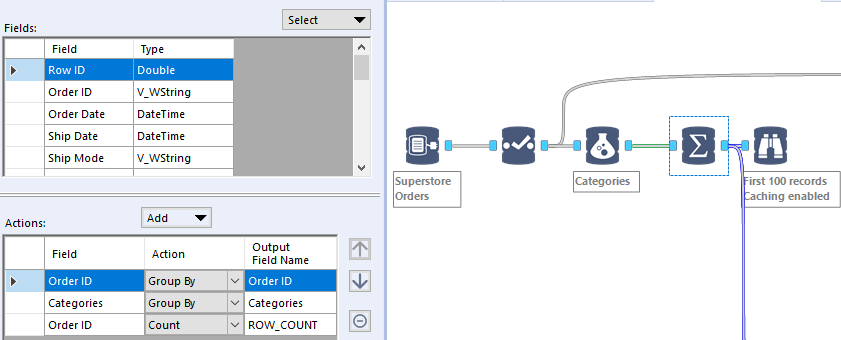
An additional trick to perform those calculations with a unique tool, when they can be placed at the beginning of a workflow, is to use a Snowflake View:
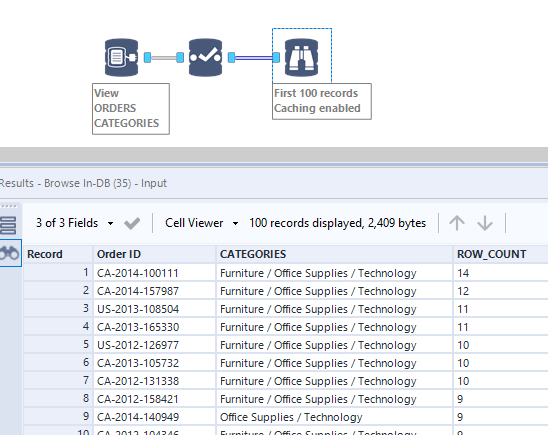
The view is defined in Snowflake with this script to run once:
-- Orders with Categories
CREATE OR REPLACE VIEW "DEMO_DB"."PUBLIC"."ORDERS_CATEGORIES" COMMENT = 'Count line items and concatenated Categories per Order' AS
WITH ORDER_CATEGORIES AS (SELECT "Order ID", LISTAGG( DISTINCT "Category",' / ' ) WITHIN GROUP (order by "Category") OVER ( PARTITION BY "Order ID" ) as "CATEGORIES" from "DEMO_DB"."PUBLIC"."SUPERSTORE92")
SELECT "Order ID", "CATEGORIES", count("Order ID") as ROW_COUNT
from ORDER_CATEGORIES
GROUP BY 1,2
order by ROW_COUNT DESC
;Unfortunately, it has to be defined as a view, which at least does not store anything, because Alteryx INDB will not accept CTEs in its Query Builder:
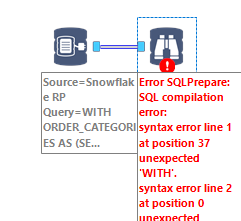
There you have it, a variety of scalable approaches to tackle complex string concatenations!