
I already wrote a couple of posts on the topic of Automation of Operations using Alteryx, but I felt an update was in order, as the possibilities evolve so fast lately. I gauged some interest on the topic as well while presenting some of this content to an audience of data Analysts at Inspire 2016. Here is the video of the presentation.
As an Analyst, why should I care about Operations? In no particular order:
- I want to deliver the freshest possible data, to ensure relevance, as business evolves fast
- I want to expand my reach and cover new topics, while keeping the lights on those already proven valuable, and move on
- I want to capture and code complex dependencies in my data, only once, when I discover them. Repetitive attention to the same tasks is a waste of my beautiful mind
- I want to leverage more of the off hours processing cycles I have, by scheduling smartly
I understand that a lot of businesses don’t have their own analyst and instead outsource to a third party like understanding data, a data consultancy, to improve their operations. It definitely makes things easier; as the amount of data is just so large, it is difficult to ensure the right data is being used for financial gains while mitigating poor data. For companies that are just starting out or the ones who are yet to make the shift to the digital world, proper management of a huge database can be of high priority. Therefore, the need for data governance services for such companies is real, and a really smart way of boosting productivity. However, my company is lucky enough to have a team that analyzes and puts together data. Controlling Operations is also part of my vision for the agile Analyst, who’s on top of the whole chain of data, from the moment transactions get extracted from the source system to the moment analysis is consumed and interpreted by the largest audience of stakeholders. The Analyst can henceforth become confidently accountable for data integrity, as he can intervene at each step of the processing, between Alteryx and her publishing tool(s) of choice (Tableau, Power BI, Qlik, …).
Operations is a process traditionally covered by IT departments, right? Operations, which consist in automating a ad hoc analysis into a repeatable process that can be scheduled and monitored for data integrity, is definitely a more technical than business endeavour. IT managers spend so much time using resources such as time series analysis to ensure the data collected is relevant and helpful for the business to continue day-to-day operations. Yet, Alteryx makes it palatable enough for a non coding Analyst to run operations with minimal dependencies on IT, beyond the initial setup of servers and credentials. IT resource can then be allocated on more technical topics, with the analysts and their endless list of tickets off their back! This constitutes perhaps the next frontier attained by the Self Service Analytics revolution? Let’s shine some light on the options already available to Analysts…
 Like for many things, Operations require decisions along a trade off: Resiliency vs. Efficiency.
Like for many things, Operations require decisions along a trade off: Resiliency vs. Efficiency.
Efficiency involves complexity and dependencies, Resiliency involves simplicity and robustness. I see those choices as the fun vs. effort side of a game of tug of war. Alteryx offers a variety of options from Resiliency to Efficiency, and you can pick the most appropriate to serve your business needs, mix and match, evolve along the way at your pace, just like I do as I keep discovering new ways to automate. I will group those options from Resilient to Efficient this way:
- Simple Independent Schedules
- Normalized Sequential Workflows
- Scalable and Fast Complex Operations with a buffer Database
To proceed throughout that journey towards State of the Art Analyst controlled Operations using Alteryx, I will illustrate with workflows based on a pretty simple business scenario using the NorthWind sample database. NorthWind is a wholesale food products company, operating world wide, and as Analyst, I have access to the ERP’s DB which gives me a set of normalized tables (available here) connecting like that:
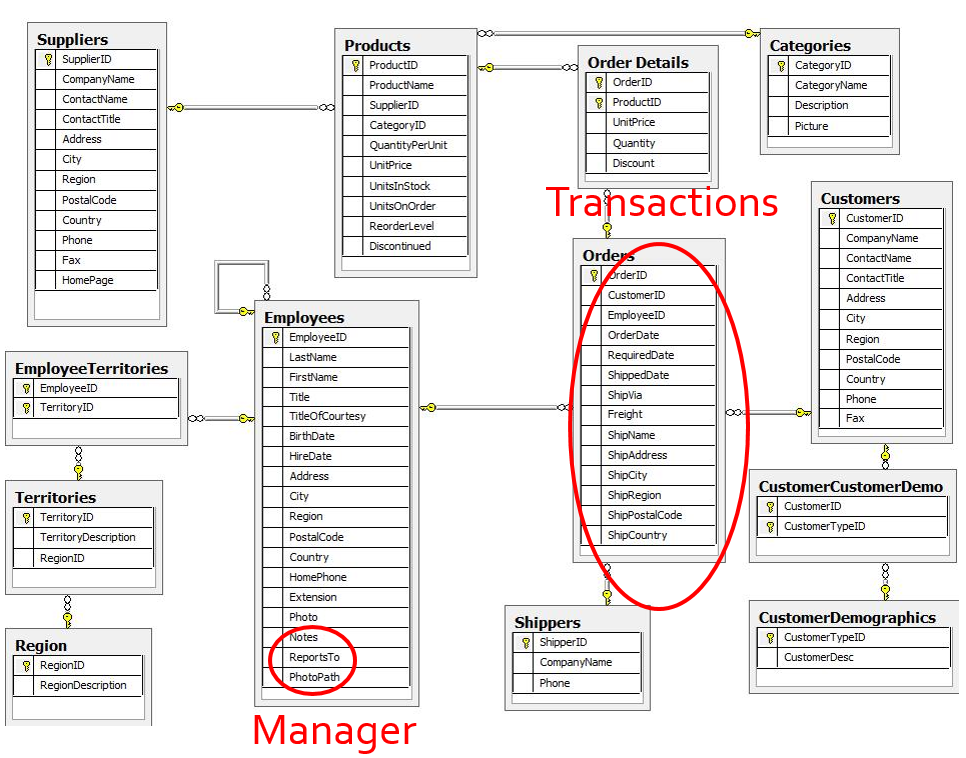 And using this DB, I need to produce a series of analytics such as Sales by Geo, Sales Rep, Sales Rep Manager, Product Trends, Customer basket analysis, you name it… The final product would look like this in Tableau:
And using this DB, I need to produce a series of analytics such as Sales by Geo, Sales Rep, Sales Rep Manager, Product Trends, Customer basket analysis, you name it… The final product would look like this in Tableau:
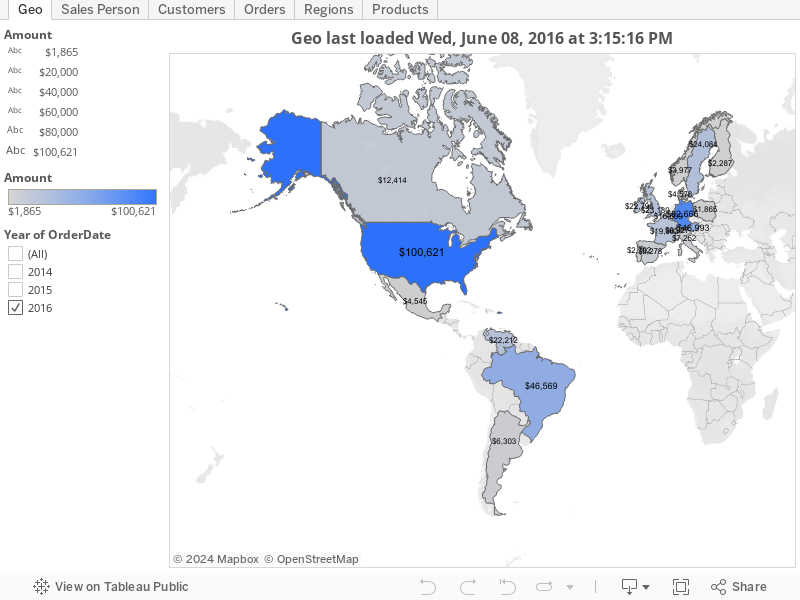
However, the business is alive, orders and shipments come every day, so the conversion from this set of tables to a TDE file suitable for Tableau to work with, should be ideally automated, to get always the freshest data.
I will now walk you through the details of that series of modeling options listed above, which is by no mean exhaustive, and is only intended to excite your creativity. Also note that there is no ONE PROPER WAY to achieve the desired result. There is a variety of options, and each will make sense in a peculiar context, or at a specific stage of maturity of your operations. All of them can actually peacefully coexist, depending on your needs and business priorities! At least you will be aware of options you might not have come across before…
1. Simple Independent Workflow
With Prerequisites 1 and 3
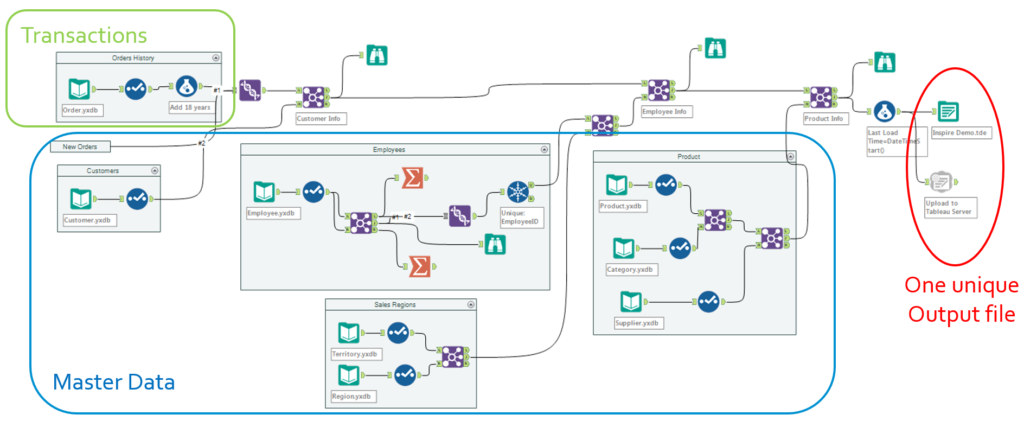
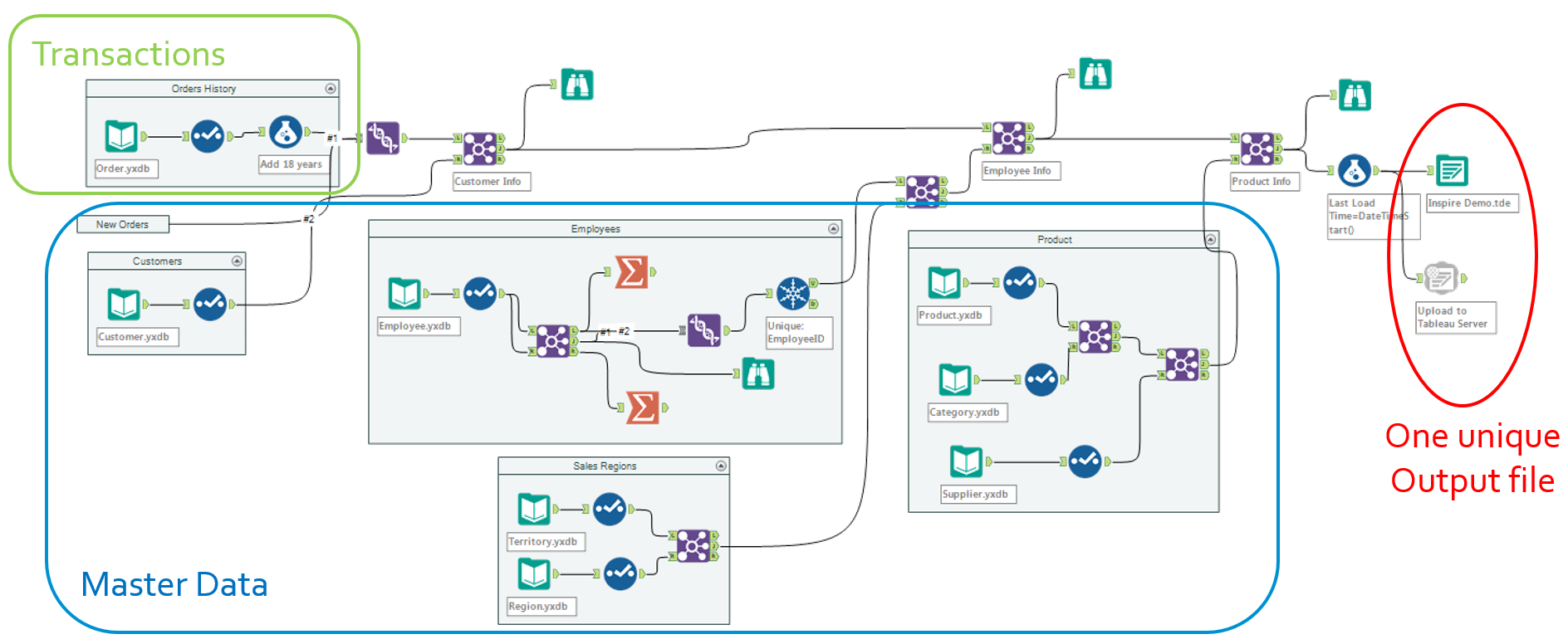
This workflow is the plain vanilla version, that most analysts would start designing when exploring and prototyping a new domain. That workflows pulls systematically all required data sets from each relevant table, and assembles them in one go, before leveraging the Upload Macro labeled as Prerequisite 3 below to upload to the publishing tool, Tableau here. To operationalize that workflow, all it takes is to schedule it, leveraging the Scheduler feature of Alteryx (Prerequisite 1):
 The benefits of that option is that it quite easy to develop, easy to schedule and monitor, and is extremely reliable, as it is self-contained with 0 dependency. The downside is that it gets inefficient really soon, when building a second data set for instance: why reloading ALL the master data every single time? In this example, if I expand my analysis further than Sales Orders towards quota attainment for instance, why reloading again the employees and Managers I already have? Then there is a chance of discrepancy between the way I pull Managers when I analyze Sales Orders vs. when I analyze quota attainment… Hence, the temptation to normalize progressively to mitigate those downsides…
The benefits of that option is that it quite easy to develop, easy to schedule and monitor, and is extremely reliable, as it is self-contained with 0 dependency. The downside is that it gets inefficient really soon, when building a second data set for instance: why reloading ALL the master data every single time? In this example, if I expand my analysis further than Sales Orders towards quota attainment for instance, why reloading again the employees and Managers I already have? Then there is a chance of discrepancy between the way I pull Managers when I analyze Sales Orders vs. when I analyze quota attainment… Hence, the temptation to normalize progressively to mitigate those downsides…
2. Normalized Sequential Workflows
First Stage with Prerequisites 1 and 3
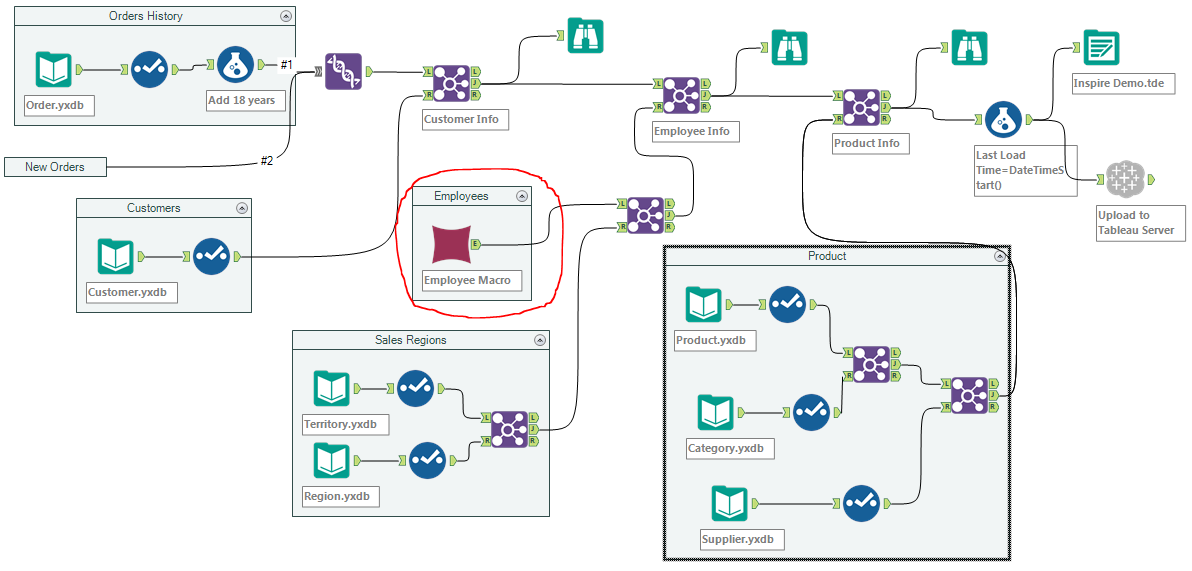 The first stage to normalize workflows is to introduce Alteryx Macros, as depicted above in the red circle. A Macro is a special type of workflow, with extension .yxmc instead of .yxmd, which is meant to be inserted into workflows from a right click on the canvas:
The first stage to normalize workflows is to introduce Alteryx Macros, as depicted above in the red circle. A Macro is a special type of workflow, with extension .yxmc instead of .yxmd, which is meant to be inserted into workflows from a right click on the canvas:
 and must include either an Input, an Output, or both. Here is how the Employee Macro looks like:
and must include either an Input, an Output, or both. Here is how the Employee Macro looks like:
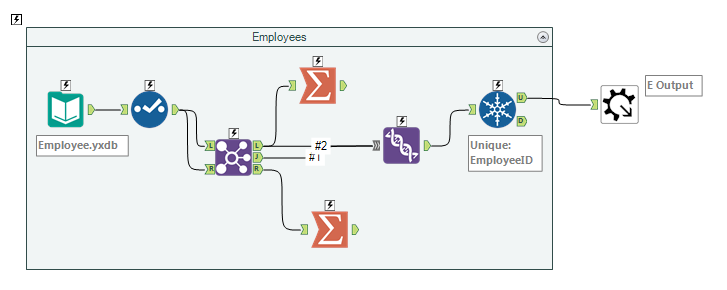 It is now available to be inserted into all the workflows that will need Employees master data, including the logic handling the recursive hierarchy, which will assign them a Manager. This logic will be centrally run and managed once from that macro. In this example, we can go further and create a Macro for each of the process likely to be re-used, such as Product, Customer, Sales Regions. Macros are really great to ensure consistency and not to reinvent the wheel every time the same action is needed, yet they still entail that the Employee Master Data logic will be run each time it is needed, which is not yet the most efficient approach.
It is now available to be inserted into all the workflows that will need Employees master data, including the logic handling the recursive hierarchy, which will assign them a Manager. This logic will be centrally run and managed once from that macro. In this example, we can go further and create a Macro for each of the process likely to be re-used, such as Product, Customer, Sales Regions. Macros are really great to ensure consistency and not to reinvent the wheel every time the same action is needed, yet they still entail that the Employee Master Data logic will be run each time it is needed, which is not yet the most efficient approach.
Second Stage with Prerequisites 1 and 3
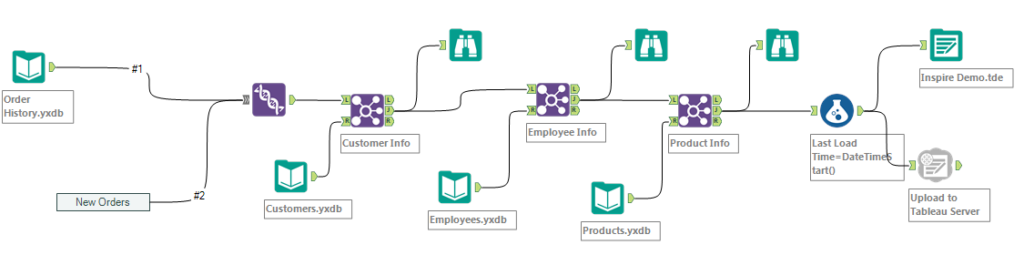
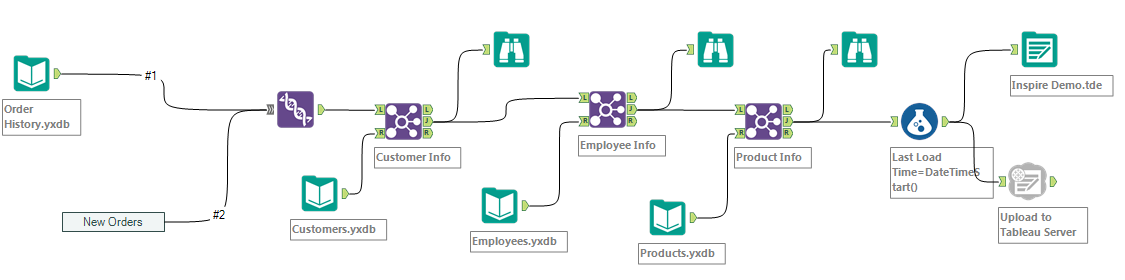
In this option, we focus on running extractions only once, store the output on the Alteryx Server or on the hard drive of the Alteryx Designer as a .yxdb efficient Alteryx Data data base format. Note that the .yxdb format is open source and documented.
We actually break down the initial independent workflow into several sub workflows, which will be scheduled to run prior to that one, which will assemble all the pieces into an output loaded into the Publishing tool. It requires more careful scheduling, as the number of schedules grow from 1 to 5 in this example, but it is still manageable. Here, those sub workflows can also be re-purposed to serve other analytics needs, just like a macro, but they need to run only once.
Third Stage with Prerequisites 1, 2 and 4
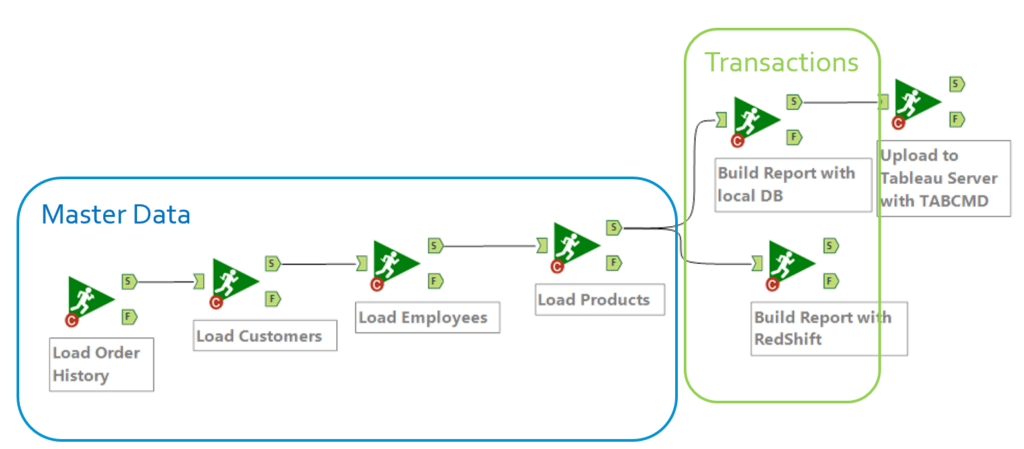 This option, built upon Runner Macros (prerequisite 4), is the one taking normalization the furthest, while still being easy and efficient to maintain. It is effectively a meta workflow, running other sub workflows in sequence, and it only needs to be scheduled once! It offers dependencies on success and failure which are not available if you schedule a series of workflows as we did above on the second stage.
This option, built upon Runner Macros (prerequisite 4), is the one taking normalization the furthest, while still being easy and efficient to maintain. It is effectively a meta workflow, running other sub workflows in sequence, and it only needs to be scheduled once! It offers dependencies on success and failure which are not available if you schedule a series of workflows as we did above on the second stage.
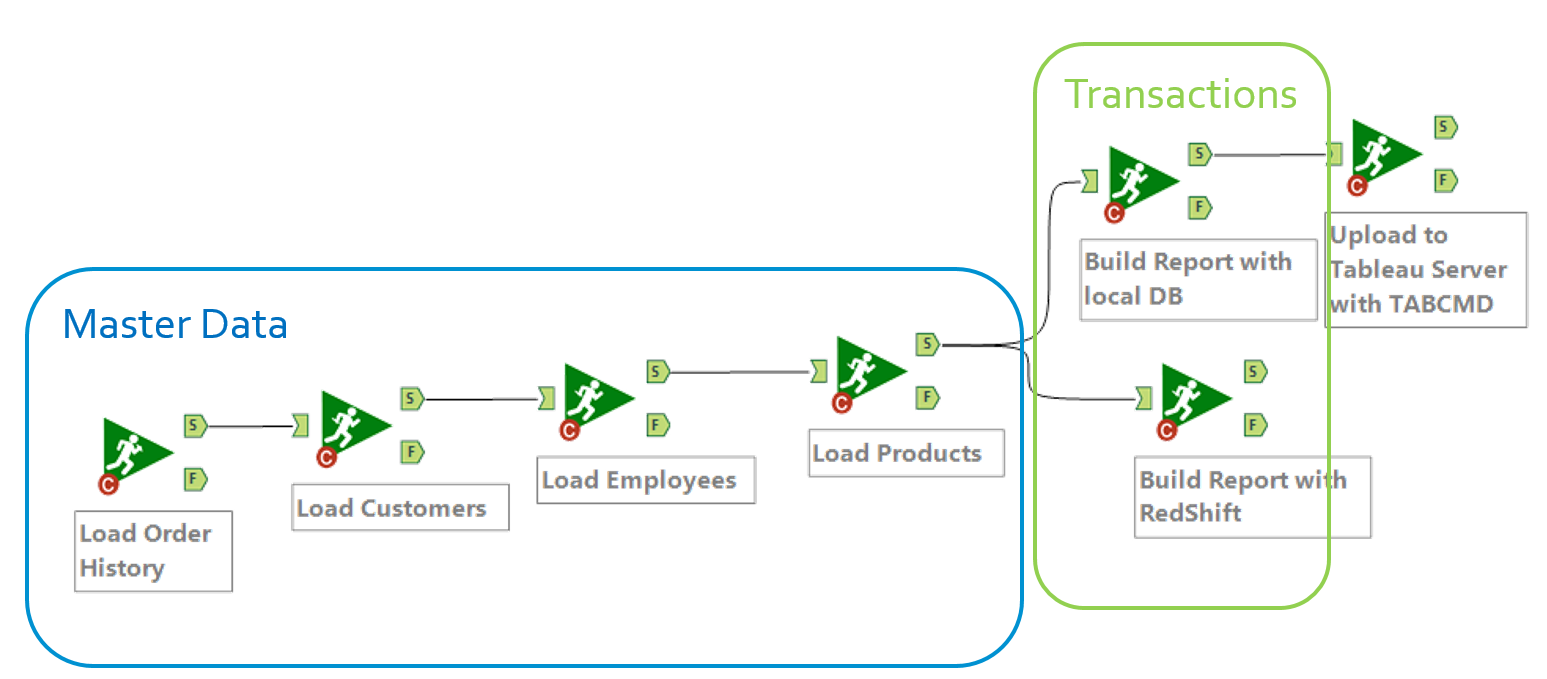
3. Scalable and Fast Complex Operations
With All Prerequisites
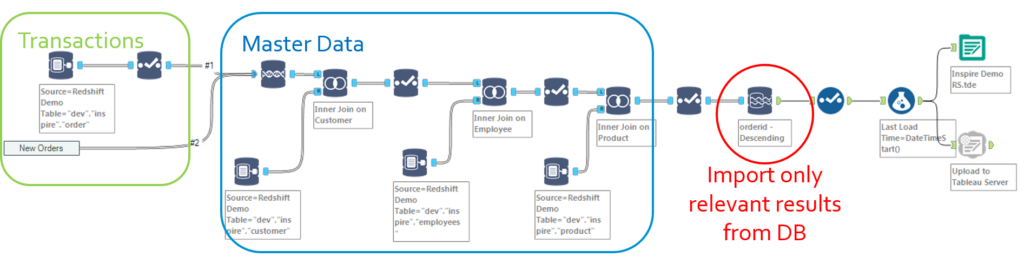
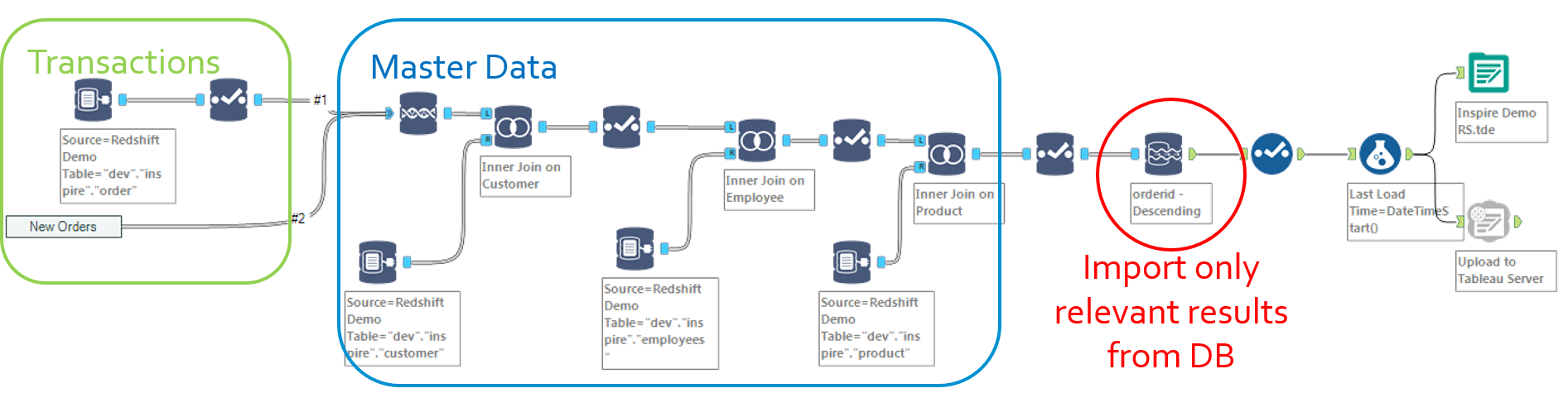
Now let’s say your Alteryx activity has expanded so much that several analysts are starting to trade macros and workflows, or you are venturing into a Big Data project with massive volumes to process. You might consider going full force, while still remaining within the comfy premises of Alteryx..
To take operations to the next level, you need to deploy a buffer database (Prerequisite 5). Options 1 and 2 can be implemented with a buffer DB. In either cases, a buffer database will relieve the Alteryx Designer from a lot of processing through INDB processing and will optimize storage since intermediary steps will remain on the DB, while only the output will be loaded into Alteryx and the Publishing tool.
For a variety of reasons, straight comparisons are not always easy to conduct, but my experience deploying Amazon RedShift vs. running into a EC2 based Alteryx Server, shows dramatic performance improvements. A workflow which used to take 15 minutes to complete in Alteryx Server, now runs in 50 seconds in RedShift. 15X faster appears to be a pretty valid rule of thumb I have observed in other instances. Nevertheless, here is my back pocket disclaimer: YMMV…
Besides the sheer performance gains, such a setup with a buffer DB opens up additional modeling possibilities:
- You can now develop delta extractions, which will only pick up from the source system the net new entries since the last time operations were run, to update the previously transferred transactions stored in the DB. This is especially relevant for Master Data and can relieve many obstacles on the critical path of your operations. This should make your IT friends happy as well by relieving their servers from those repeated loads. All it takes is to use the transaction date for transactions (e.g. Sale Order Date for Sales Orders) and the Date Last Changed field for Master Data on the source table.
- You can store intermediary stages of the processing in the DB, which are not always publishing worthy, but can accelerate the overall processing for repeated results, just like a macro does it for repeated code.
- You can time stamp Master Data even though there was no such historical values in your Source System. All it takes is to add in the DB a Date From and a Date To, and populate accordingly when loading the Master Data. Downstream workflows will read either the most recent with no Date To, or a historical value based on a reference date.
Prerequisites:
- Alteryx Scheduler:
The Alteryx Scheduler is a component that lets you schedule the execution of workflows within Designer, either on a recurring basis or at a specific time in the future. Scheduler is available as a quick upgrade from a regular Alteryx Designer license, or from within Alteryx Server.
With Desktop Automation, you can run schedules from your PC, which is a quick & easy way to deploy and operate if you are on your own.
With Server, besides running from a Server which should be always on, you get additional features:
1. Run several Workloads Simultaneously
2. Share Workloads by publishing them
3. Data Governance with data access control - Script Tools:
For your publishing tools, such as Tableau, there are often some scripting tools available if you know where to look, which let you automate tasks through scripts. For Tableau, it is called TABCMD, and can be installed on your Alteryx instance for free following those instructions.
Those script tools work wonders in combination with the Run Command tool of Alteryx, to upload in batches for instance, or generate screen shots for archiving. - Publish Macros:
Publish macros are FREE tools released and maintained by Alteryx to take a workflow output and load/refresh directly into your publishing tool of choice. These tools are released separately from the main Designer as they are on a different refresh cycle. They install on your Alteryx Designer instance, and become additional tools found under the Connectors Tab. Here is one for Tableau Server or Online, and one for Microsoft Power BI. More to come… - Runner Macros:
Runner Macros are also free Alteryx tools released by an Alteryx engineer, Adam Riley, which are not yet part of the standard release of Alteryx. yet, integration of those jewels is, obviously, on the road map. The Runner tool lets you kick off running the first workflow, while the Conditional Runner lets you implement dependencies for the subsequent workflows. Download them Here. - Buffer Database:
A Buffer DB is by no means required, and certainly adds complexity to the management of the analytics environment. Yet, the benefits are alluring enough to consider having one. It can be a On Premise DB, such as Oracle, MS SQL Server, Apache Hive or Spark, or it can be a Cloud service, such as Amazon RedShift, MS Azure SQL, Cloudera, but it must be INDB compatible to ensure optimization. If you already have existing developments on those DBs, INDB will let you port your SQL code to be run from within Alteryx.