
Data for analytics can be structured in two different ways: Wide or Long. Here is an illustration of the two types of format for the same data set:
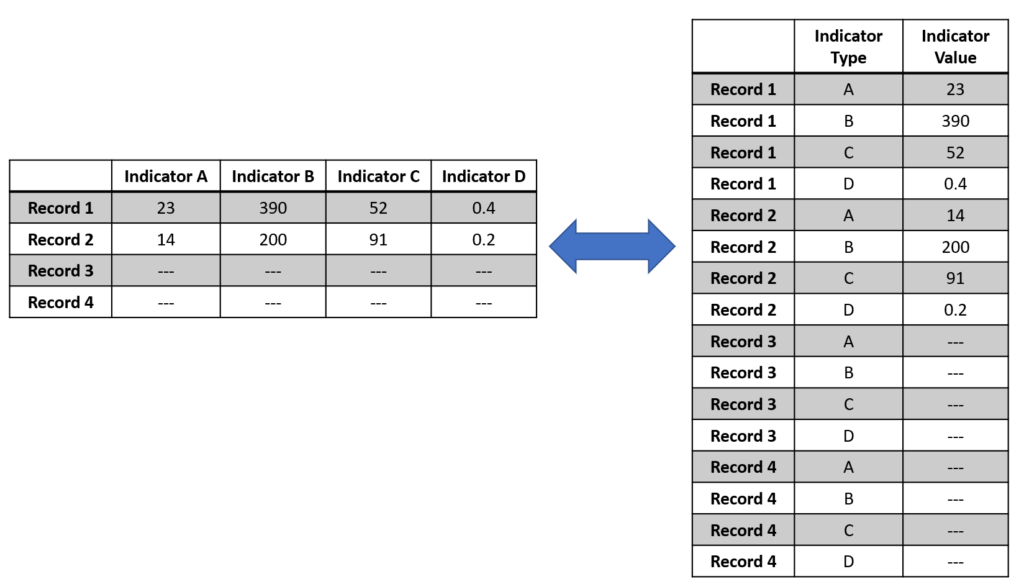
When would you use one vs. the other? In general, wide models work better for analytical models and offer a better visual layout for humans, whereas the long model works better for columnar DBs like Snowflake, Redshift or Tableau. Their engine is optimized to crunch data at scale within columns.
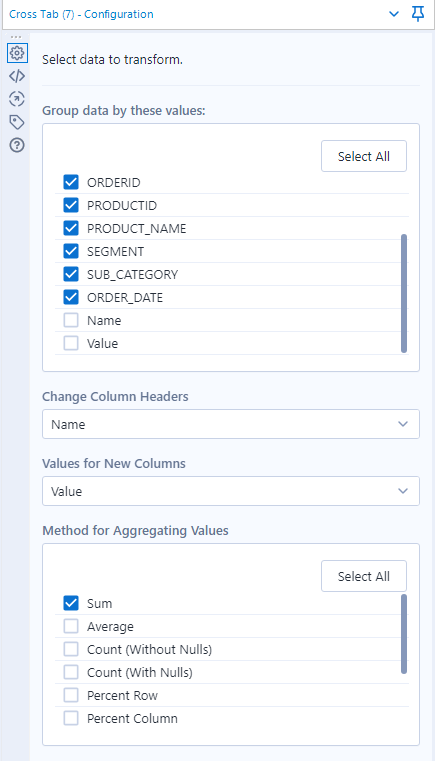
Now suppose you use Snowflake as a staging area for your analytics, which I highly recommend. You ought to write your data in the Long format. How do you perform that conversion, sometimes called reshaping a table from wide to long? That operation is also called to transpose (Alteryx), unpivot (Snowflake, BigQuery), pivot Columns to Rows (Tableau Prep) or melt a table (Panda). We will also cover the flip side operation, from Long to Wide, also called to cross tab (Alteryx), pivot (Snowflake, BigQuery, Panda) or pivot Rows to Columns (Tableau Prep).
Let’s get practical with a real data set!
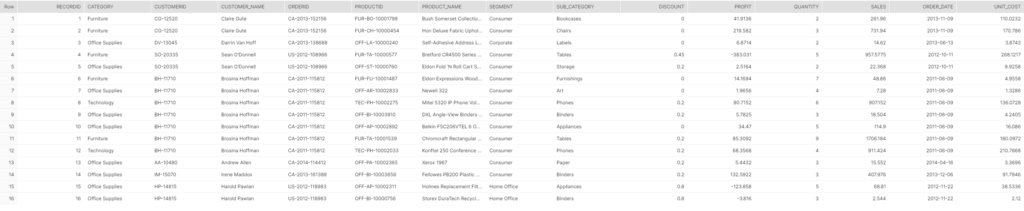
I will use the standard Super Store data set that comes with Tableau, a nice example of a wide table. I will take only 16 records that will look like this once loaded:
If you want to follow along, here is a script ready to copy to create the table in Snowflake and another to load the 16 records:
--- Create Table
create or replace table Orders_Demo (
RecordId Double,
Category varchar
,CustomerId varchar
,Customer_Name varchar
,OrderId varchar
,ProductId varchar
,Product_Name varchar
,Segment varchar
,Sub_Category varchar
,Discount Double
,Profit Double
,Quantity Double
,Sales Double
,Order_Date Date
);
--- Populate table
insert into Orders_Demo (RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,Discount,Profit,Quantity,Sales) values
(1,'Furniture', 'CG-12520', 'Claire Gute', 'CA-2013-152156', '2013-11-09', 'FUR-BO-10001798', 'Bush Somerset Collection Bookcase', 'Consumer', 'Bookcases',0,41.9136,2,261.96
),(2,'Furniture', 'CG-12520', 'Claire Gute', 'CA-2013-152156', '2013-11-09', 'FUR-CH-10000454', 'Hon Deluxe Fabric Upholstered Stacking Chairs, Rounded Back', 'Consumer', 'Chairs',0,219.582,3,731.94
),(3,'Office Supplies', 'DV-13045', 'Darrin Van Huff', 'CA-2013-138688', '2013-06-13', 'OFF-LA-10000240', 'Self-Adhesive Address Labels for Typewriters by Universal', 'Corporate', 'Labels',0,6.8714,2,14.62
),(4,'Furniture', 'SO-20335', 'Sean O''Donnell', 'US-2012-108966', '2012-10-11', 'FUR-TA-10000577', 'Bretford CR4500 Series Slim Rectangular Table', 'Consumer', 'Tables',0.45,-383.031,5,957.5775
),(5,'Office Supplies', 'SO-20335', 'Sean O''Donnell', 'US-2012-108966', '2012-10-11', 'OFF-ST-10000760', 'Eldon Fold ''N Roll Cart System', 'Consumer', 'Storage',0.2,2.5164,2,22.368
),(6,'Furniture', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'FUR-FU-10001487', 'Eldon Expressions Wood and Plastic Desk Accessories, Cherry Wood', 'Consumer', 'Furnishings',0,14.1694,7,48.86
),(7,'Office Supplies', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'OFF-AR-10002833', 'Newell 322', 'Consumer', 'Art',0,1.9656,4,7.28
),(8,'Technology', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'TEC-PH-10002275', 'Mitel 5320 IP Phone VoIP phone', 'Consumer', 'Phones',0.2,90.7152,6,907.152
),(9,'Office Supplies', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'OFF-BI-10003910', 'DXL Angle-View Binders with Locking Rings by Samsill', 'Consumer', 'Binders',0.2,5.7825,3,18.504
),(10,'Office Supplies', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'OFF-AP-10002892', 'Belkin F5C206VTEL 6 Outlet Surge', 'Consumer', 'Appliances',0,34.47,5,114.9
),(11,'Furniture', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'FUR-TA-10001539', 'Chromcraft Rectangular Conference Tables', 'Consumer', 'Tables',0.2,85.3091999999998,9,1706.184
),(12,'Technology', 'BH-11710', 'Brosina Hoffman', 'CA-2011-115812', '2011-06-09', 'TEC-PH-10002033', 'Konftel 250 Conference phone - Charcoal black', 'Consumer', 'Phones',0.2,68.3568,4,911.424
),(13,'Office Supplies', 'AA-10480', 'Andrew Allen', 'CA-2014-114412', '2014-04-16', 'OFF-PA-10002365', 'Xerox 1967', 'Consumer', 'Paper',0.2,5.4432,3,15.552
),(14,'Office Supplies', 'IM-15070', 'Irene Maddox', 'CA-2013-161389', '2013-12-06', 'OFF-BI-10003656', 'Fellowes PB200 Plastic Comb Binding Machine', 'Consumer', 'Binders',0.2,132.5922,3,407.976
),(15,'Office Supplies', 'HP-14815', 'Harold Pawlan', 'US-2012-118983', '2012-11-22', 'OFF-AP-10002311', 'Holmes Replacement Filter for HEPA Air Cleaner, Very Large Room, HEPA Filter', 'Home Office', 'Appliances',0.8,-123.858,5,68.81
),(16,'Office Supplies', 'HP-14815', 'Harold Pawlan', 'US-2012-118983', '2012-11-22', 'OFF-BI-10000756', 'Storex DuraTech Recycled Plastic Frosted Binders', 'Home Office', 'Binders',0.8,-3.816,3,2.544
);
In Snowflake with a SQL command
I am adding a cost column as I feel it is missing from the dataset, and is much easier to add in a wide table than to a long:
--- Add cost column
ALTER TABLE Orders_Demo ADD COLUMN UNIT_COST DOUBLE as ((SALES - PROFIT)/QUANTITY);Unpivot from Wide to Long
Here is the traditional SQL way to convert a wide table to long, which will make it easier to compute ROI calcs in Tableau, using UNION commands to create those new rows:
--- Traditional Unpivot to Transpose
CREATE OR REPLACE TABLE "INTERNAL"."PUBLIC"."ORDERS_DEMO_LONG" COMMENT = 'Based on ORDERS_DEMO' AS
SELECT RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,'DISCOUNT' as Indicator_Type,DISCOUNT as Indicator from Orders_Demo
UNION
SELECT RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,'PROFIT' as Indicator_Type,PROFIT as Indicator from Orders_Demo
UNION
SELECT RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,'QUANTITY' as Indicator_Type,Quantity as Indicator from Orders_Demo
UNION
SELECT RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,'SALES' as Indicator_Type,Sales as Indicator from Orders_Demo
UNION
SELECT RecordID,Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category,'UNIT_COST' as Indicator_Type,UNIT_COST as Indicator from Orders_Demo
ORDER by RecordID ;A bit cumbersome code isn’t it? We get from 16 records to 80 records with less columns. Yet, Snowflake offers a more elegant solution using the UNPIVOT function:
--- UNPIVOT to Transpose / get long table
CREATE OR REPLACE TABLE "INTERNAL"."PUBLIC"."ORDERS_DEMO_LONG" COMMENT = 'Based on ORDERS_DEMO' AS
WITH "Orders_demo_Selected" as (SELECT CUSTOMERID,CUSTOMER_NAME,ORDERID,ORDER_DATE,PRODUCTID,PRODUCT_NAME,CATEGORY,SEGMENT,SUB_CATEGORY,DISCOUNT,PROFIT,QUANTITY,SALES,UNIT_COST
from "INTERNAL"."PUBLIC"."ORDERS_DEMO")
SELECT * from "Orders_demo_Selected"
unpivot(indicator for Indicator_Type in (DISCOUNT,PROFIT,QUANTITY,SALES,UNIT_COST) )
;
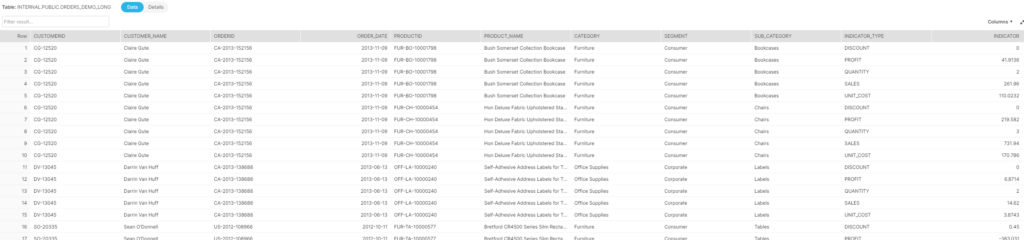
We started with 16 records and the resulting table ORDERS_DEMO_LONG has 80 records and looks like this:
Pivoting back to 16 records
To go the reverse way, that is from Long to Wide, I can use the traditional SQL way:
--- Traditional pivot to Cross Tab / get wide table
SELECT Category,CustomerId,Customer_Name,OrderId,Order_Date,ProductId,Product_Name,Segment,Sub_Category, MAX(CASE when Indicator_Type='DISCOUNT' then indicator else NULL END) as DISCOUNT,
MAX(CASE when Indicator_Type='PROFIT' then indicator else NULL END) as PROFIT, MAX(CASE when Indicator_Type='QUANTITY' then indicator else NULL END) as QUANTITY, MAX(CASE when Indicator_Type='SALES' then indicator else NULL END) as SALES, MAX(CASE when Indicator_Type='UNIT_COST' then indicator else NULL END) as UNIT_COST
from "INTERNAL"."PUBLIC"."ORDERS_DEMO_LONG"
GROUP BY 1,2,3,4,5,6,7,8,9
;Or again a more elegant Snowflake PIVOT function using this syntax:
--- PIVOT to Cross Tab / get wide table
select *
from ORDERS_DEMO_LONG
pivot(sum(INDICATOR) for INDICATOR_TYPE IN ('SALES','QUANTITY','DISCOUNT','PROFIT','UNIT_COST'))
;Easier to read, isn’t it? It seems to run a bit faster too than the traditional way, but I am not positive as there are some cache effects I don’t fully comprehend… Anyways, I get back to 16 records, looking like this:
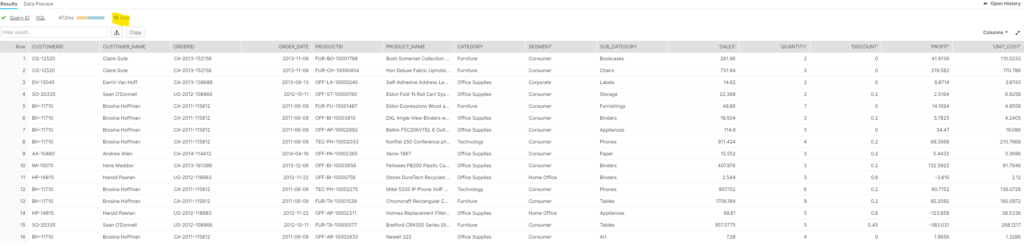
If you pay close attention to the headers of the indicators, you will notice that they are quoted… To address that quirk, you can use this syntax, which is tuning the SELECT:
--- PIVOT to get wide table with clean headers
select CUSTOMERID,CUSTOMER_NAME,ORDERID,ORDER_DATE,PRODUCTID,PRODUCT_NAME,CATEGORY,SEGMENT,SUB_CATEGORY,"'SALES'" as SALES,"'QUANTITY'" as QUANTITY,"'DISCOUNT'" as DISCOUNT,"'PROFIT'" as PROFIT,"'UNIT_COST'" as UNIT_COST
from ORDERS_DEMO_LONG
pivot(sum(INDICATOR) for INDICATOR_TYPE IN ('SALES','QUANTITY','DISCOUNT','PROFIT','UNIT_COST'))
;Those functions are fairly easy to use once you get the hang of it… We will see below that this syntax comes handy in unexpected situations..
With Alteryx
In Memory
Alteryx in memory covers very well those transformations with dedicated tools fairly easy to use.
Unpivot/Transpose
after importing the data from the Snowflake table in memory, just pick the Transpose tool from the Transform tab and expand your wide table of 16 records to a Long table of 80 records:
Here is the configuration of the tool, attributes as key columns, indicators as data columns:
Pivot / Cross Tab
to revert to a wide table, the Cross Tab tool is even easier to use to get back to 16 records:
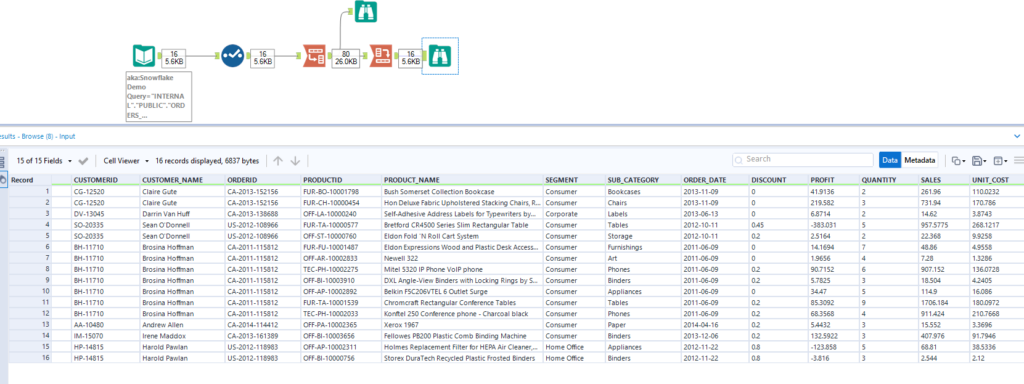
and here is the configuration of the tool:
INDB (In database)
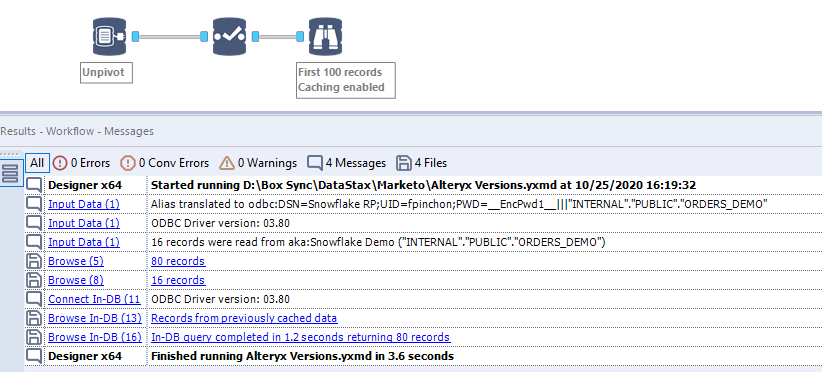
If the In Memory tools in Alteryx are time tested, there are many situations where one could benefit from performing those transformations INDB (In Database), say because the table is too large for the device running Alteryx, or because it is simply a waste of time to import the data to the memory, and then to re-export it to the database. It just makes more sense to leverage the power of the database stay INDB.
However, Alteryx does not currently provide INDB versions of the Transform and Cross Tab tools. To be fair, there is one INDB Transpose tool, but it only works with the dinosaurs of data bases, MS SQL Server and Oracle, which are not analytical DBs…
Fortunately, there is a hacky way to get those transformations done in Alteryx INDB: take the SQL scripts covered above in this post and insert them in the SQL editor tab of a Connect INDB tool without ; at the end. This approach will not work in the Formula INDB tool, as those transformations are changing the granularity and structure of the table. This can only work in the INDB Connect tool.
Pivot/ Cross Tab INDB
Simply paste the SQL script and rename the indicators in a subsequent Select tool:

Unpivot / Transpose INDB
That one is trickier, as INDB Connect tool does not accept CTEs. Therefore, use the SQL script with CTE to create a view in Snowflake, and just call the view in the Connect INDB tool…
--- UNPIVOT to Transpose / get long VIEW
CREATE OR REPLACE VIEW "INTERNAL"."PUBLIC"."ORDERS_DEMO_LONG_VIEW" COMMENT = 'Based on ORDERS_DEMO' AS
WITH "Orders_demo_Selected" as (SELECT CUSTOMERID,CUSTOMER_NAME,ORDERID,ORDER_DATE,PRODUCTID,PRODUCT_NAME,CATEGORY,SEGMENT,SUB_CATEGORY,DISCOUNT,PROFIT,QUANTITY,SALES,UNIT_COST
from "INTERNAL"."PUBLIC"."ORDERS_DEMO")
SELECT * from "Orders_demo_Selected"
unpivot(indicator for Indicator_Type in (DISCOUNT,PROFIT,QUANTITY,SALES,UNIT_COST) )Now with Connect INDB calling “INTERNAL”.”PUBLIC”.”ORDERS_DEMO_LONG_VIEW”, I get the expected 80 records:
And here are all the scripts used above gathered in a single place:
Pingback: New SQL tool for Analysts on Snowflake: Datameer | Insights Through Data