
I get to spend a lot of quality time with INDB tools, which represent 90% of my workflows. I love them, I can generate code almost at the speed of thoughts. They are fast to put together but also very powerful, especially when coupled with modern data bases such as Redshift or Snowflake, as they don’t hog any local resource.
Yet, I have been running over time into a series of issues and limitations of those tools, far from being obvious, and which all caused perplexity and time spent to address. I will share them through a blog series, and will start with a trap easy to describe, yet lethal in terms of its impact on data integrity: INDB Filter does not handle NULLs by default, unlike its cousin the In Memory Filter.
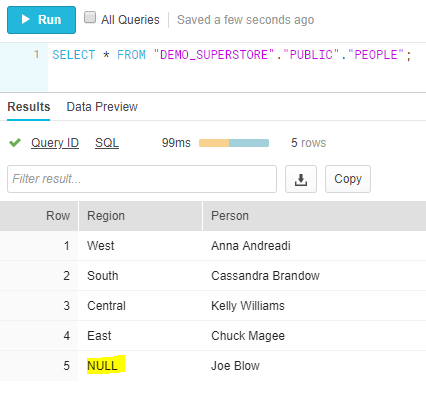
Let’s illustrate with a simple scenario, where I have this table in my DB:
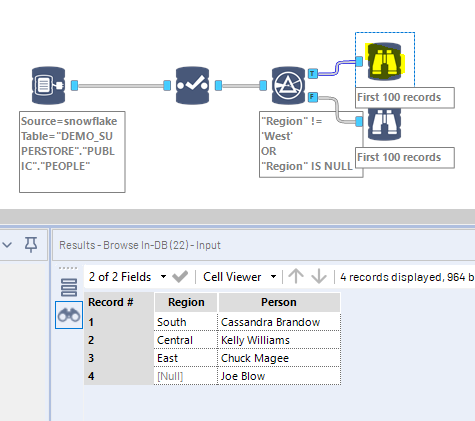
Now if set a filter to exclude the Person in Region West:
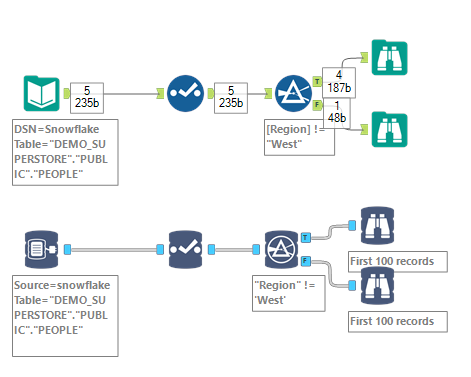
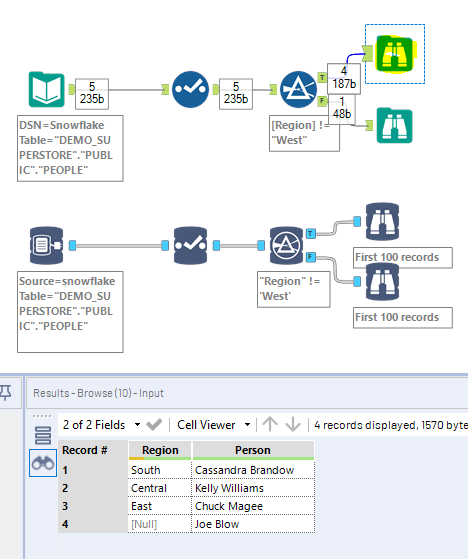
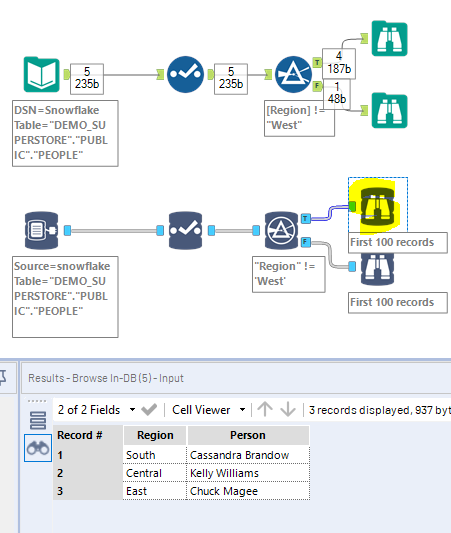
In Memory version did exclude Anna as expected, and so did the INDB version on the right, BUT Joe Blow, with a NULL Region, got lost along the way, and is nowhere to be found! Notice that there is no error message, nor any warning… INDB Filter just ate the NULL records, and that is a problem, because you are not always aware that there are some NULL values in the column…
The fact that INDB behaves with a different logic than In Memory makes me think that this is a bug or oversight, rather than a feature… And I would be in favor of addressing that bug… In the meantime, what can be done? Here is a pretty simple fix that you should apply preemptively to all your INDB Filters:
And here is another way, a little bit more involved, but can be handy if the filter logic is too complex to include NULLs:
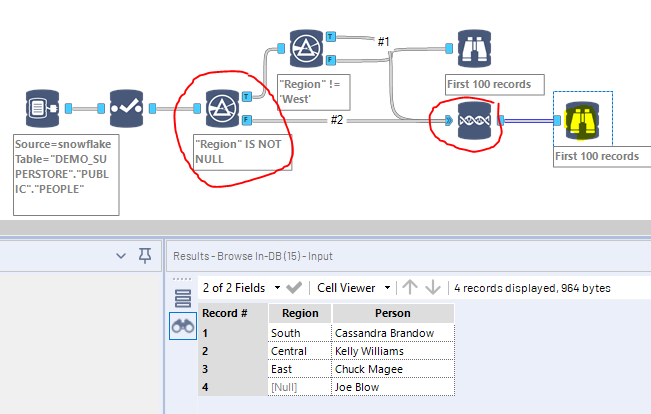
When you are missing entries at the end of a workflow, this should be the first issue to check for. Knowing that simple tip would have saved me hours of debugging… Hopefully, in the near future, I will be able to retire that post because the logic of the tool will be fixed…
Hi
I’ve just faced with this “feature”, I like the fix manually grabbing NOT NULLs
Thanks for the idea
A tickbox would be good at tool config about how to handle NULLs IMHO
Thanks
Cheers
CS